From Real Exams Exam Paper
Primary 5 Science Semestral Assessment 2 (End of Year) Paper 5
Free P5 Science SA2 Paper 5, Nemo3 Exam version, with questions, answers, and syllabus-aligned practice for Singapore students.
These static practice materials are generated from the site's syllabus and paper-generation workflow, with source and model context shown so students and parents can evaluate the material before use.
Questions
TuitionGoWhere Practice Paper - Science Primary 5
TuitionGoWhere Exam Practice (AI)
Subject: Science
Level: Primary 5
Paper: SA2 (Semestral Assessment 2)
Duration: 1 hour 45 minutes
Total Marks: 100
Name: ________________________
Class: Primary 5 _______
Date: ________________________
INSTRUCTIONS TO CANDIDATES
- Do not turn over this page until you are told to do so.
- Follow all instructions carefully.
- Answer all questions.
- For Section A, shade your answers on the Optical Answer Sheet (OAS) provided.
- For Section B, write your answers in the spaces provided in this booklet.
- The number of marks is given in brackets [ ] at the end of each question or part question.
- The total marks for this paper is 100.
SECTION A (56 marks)
For each question from 1 to 28, four options are given. One of them is the correct answer. Make your choice (1, 2, 3 or 4) and shade the correct oval on the Optical Answer Sheet (OAS). Each question carries 2 marks.
Question 1
Which of the following statements about living things is correct?
(1) All living things can make their own food.
(2) All living things reproduce by laying eggs.
(3) All living things respond to changes in their surroundings.
(4) All living things need oxygen to survive.
[2]
Question 2
The diagram below shows a cell.
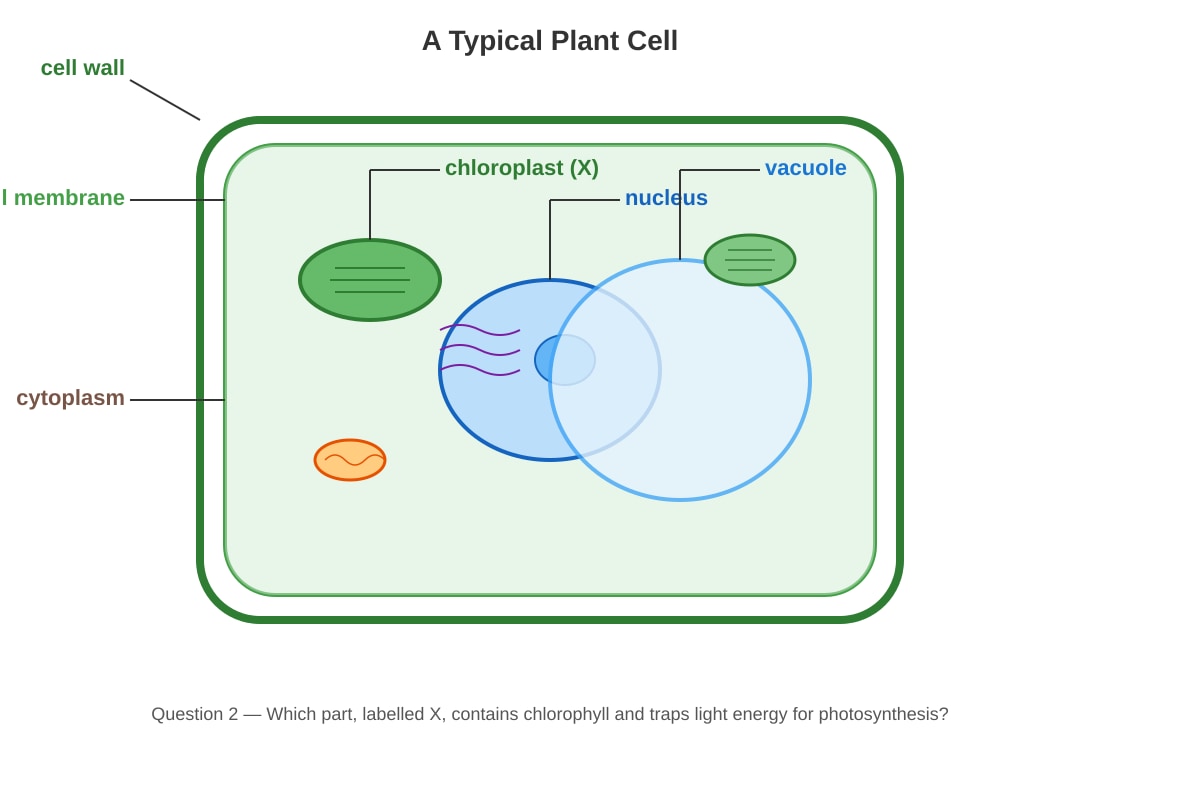
Generated diagram for Q1.
Which part, labelled X, contains chlorophyll and traps light energy for photosynthesis?
(1) Nucleus
(2) Cytoplasm
(3) Chloroplast
(4) Vacuole
[2]
Question 3
Study the classification chart below.
Image pending generation: chart for Q3.
Which of the following organisms is classified incorrectly in the chart?
(1) Fern – Non-flowering plant
(2) Mushroom – Non-flowering plant
(3) Moss – Non-flowering plant
(4) Algae – Non-flowering plant
[2]
Question 4
Four students made the following statements about microorganisms.
| Student | Statement |
|---|---|
| Ali | All microorganisms are harmful. |
| Bala | Yeast is a microorganism. |
| Cindy | Bacteria can only be seen with a microscope. |
| Devi | Mould is a type of bacteria. |
Which two students made correct statements?
(1) Ali and Bala
(2) Bala and Cindy
(3) Cindy and Devi
(4) Ali and Devi
[2]
Question 5
The diagram below shows the life cycle of a flowering plant.
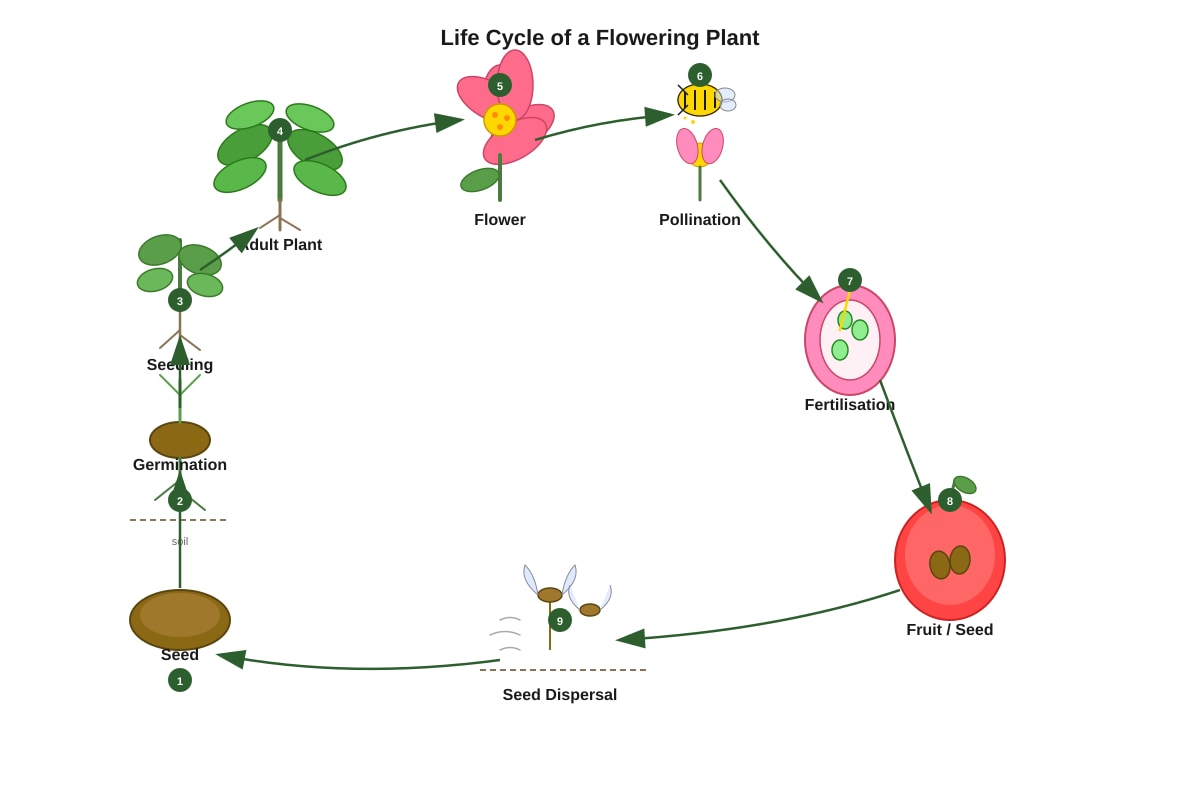
Generated diagram for Q5.
Which process occurs immediately after fertilisation?
(1) Pollination
(2) Seed dispersal
(3) Fruit development
(4) Germination
[2]
Question 6
Which of the following shows the correct order of stages in the human reproductive process?
(1) Fertilisation → Ovulation → Implantation → Development
(2) Ovulation → Fertilisation → Implantation → Development
(3) Ovulation → Implantation → Fertilisation → Development
(4) Fertilisation → Implantation → Ovulation → Development
[2]
Question 7
The diagram below shows a human sperm and a human egg.
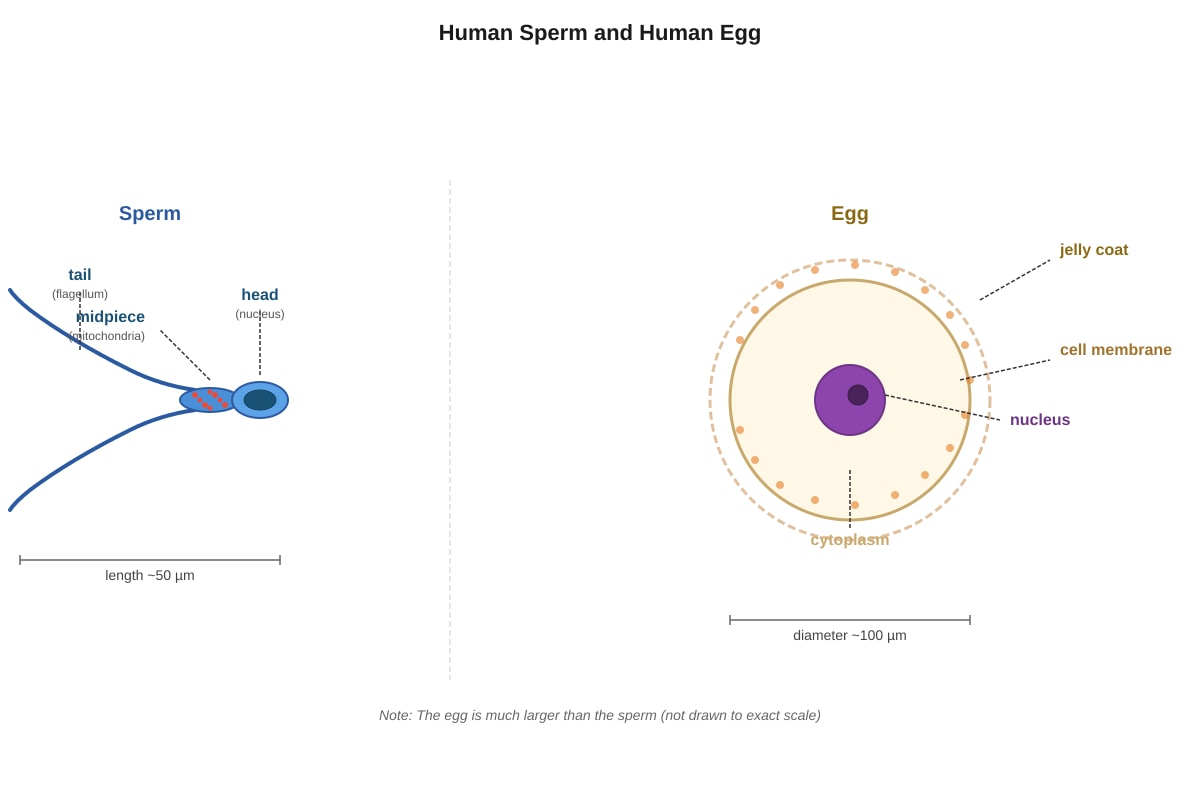
Generated diagram for Q7.
Which statement correctly compares the sperm and the egg?
(1) The sperm is larger than the egg.
(2) The sperm can move on its own but the egg cannot.
(3) Both the sperm and the egg are produced in large numbers.
(4) Both the sperm and the egg contain stored food for the embryo.
[2]
Question 8
Study the food web below.
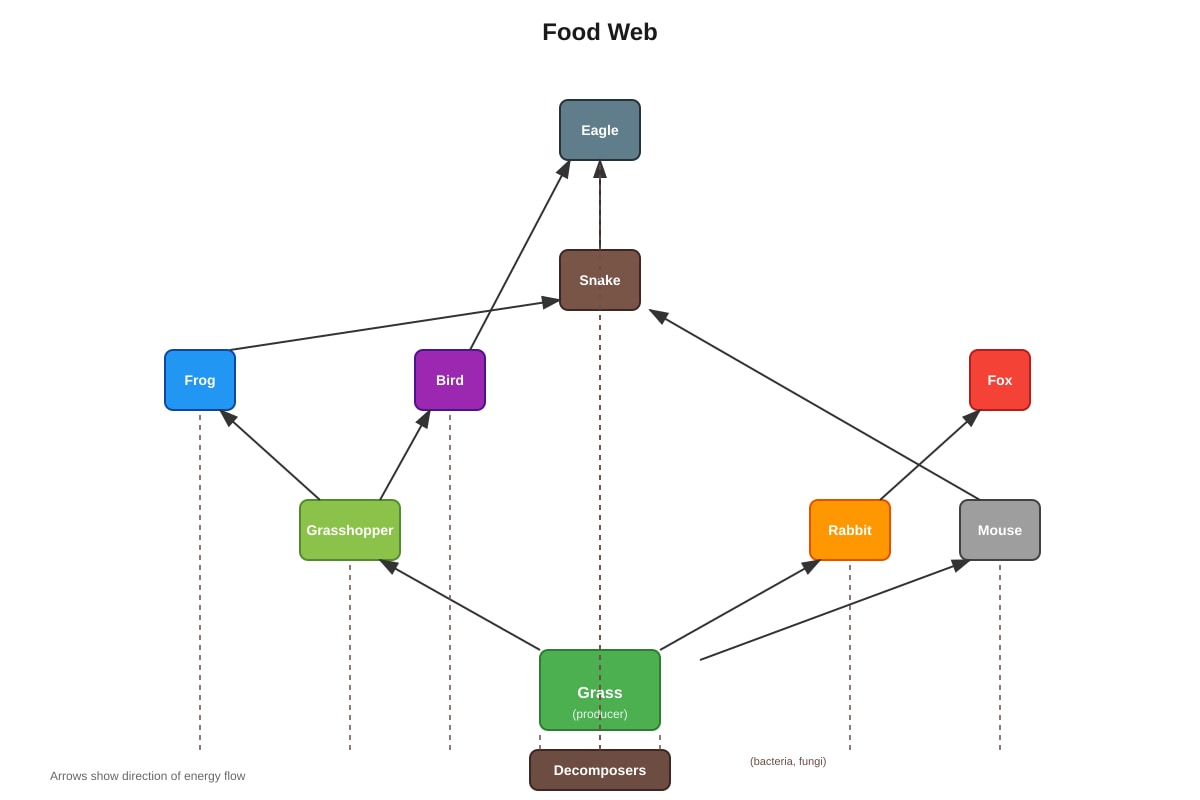
Generated diagram for Q8.
If a disease kills all the grasshoppers, which population is most likely to increase?
(1) Grass
(2) Frog
(3) Snake
(4) Eagle
[2]
Question 9
The diagram below shows the water cycle.
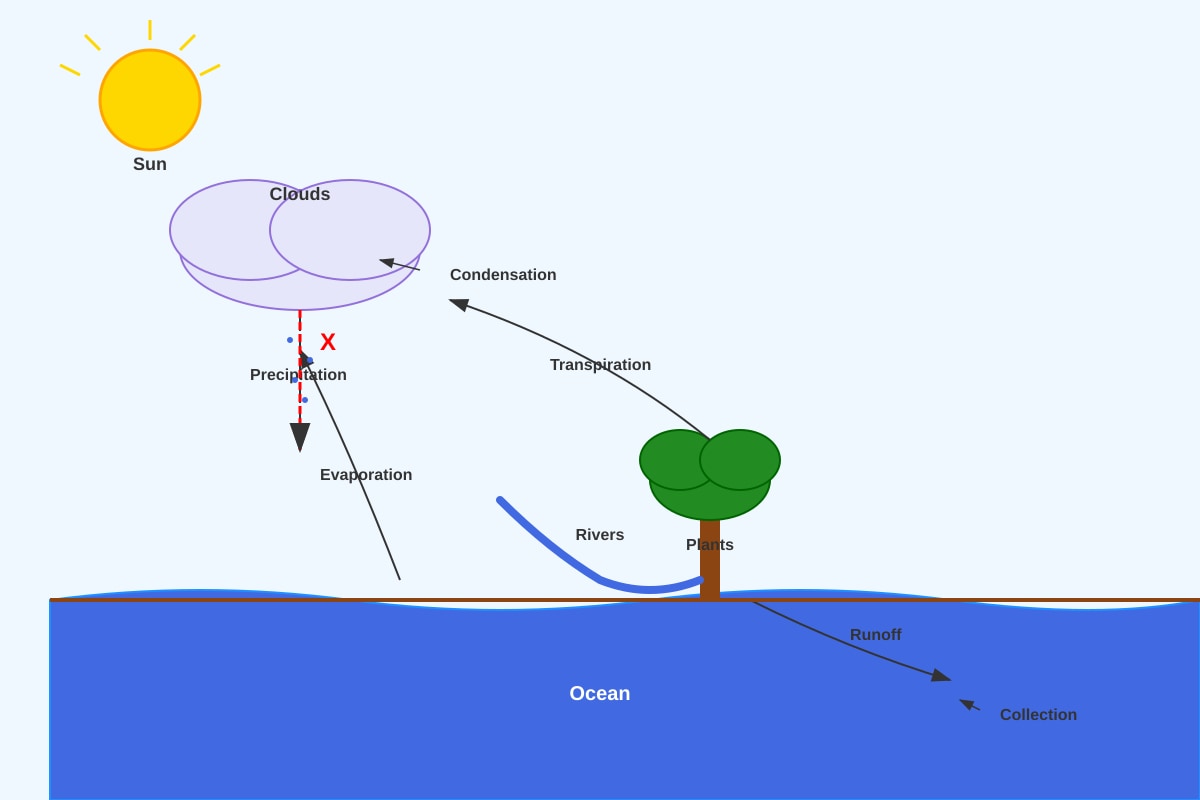
Generated diagram for Q9.
Which process is represented by the arrow labelled X pointing from the clouds to the ground?
(1) Evaporation
(2) Condensation
(3) Precipitation
(4) Transpiration
[2]
Question 10
Which of the following factors does not increase the rate of evaporation?
(1) Higher temperature
(2) Larger exposed surface area
(3) Higher humidity
(4) Stronger wind
[2]
Question 11
The diagram below shows a plant transport system.
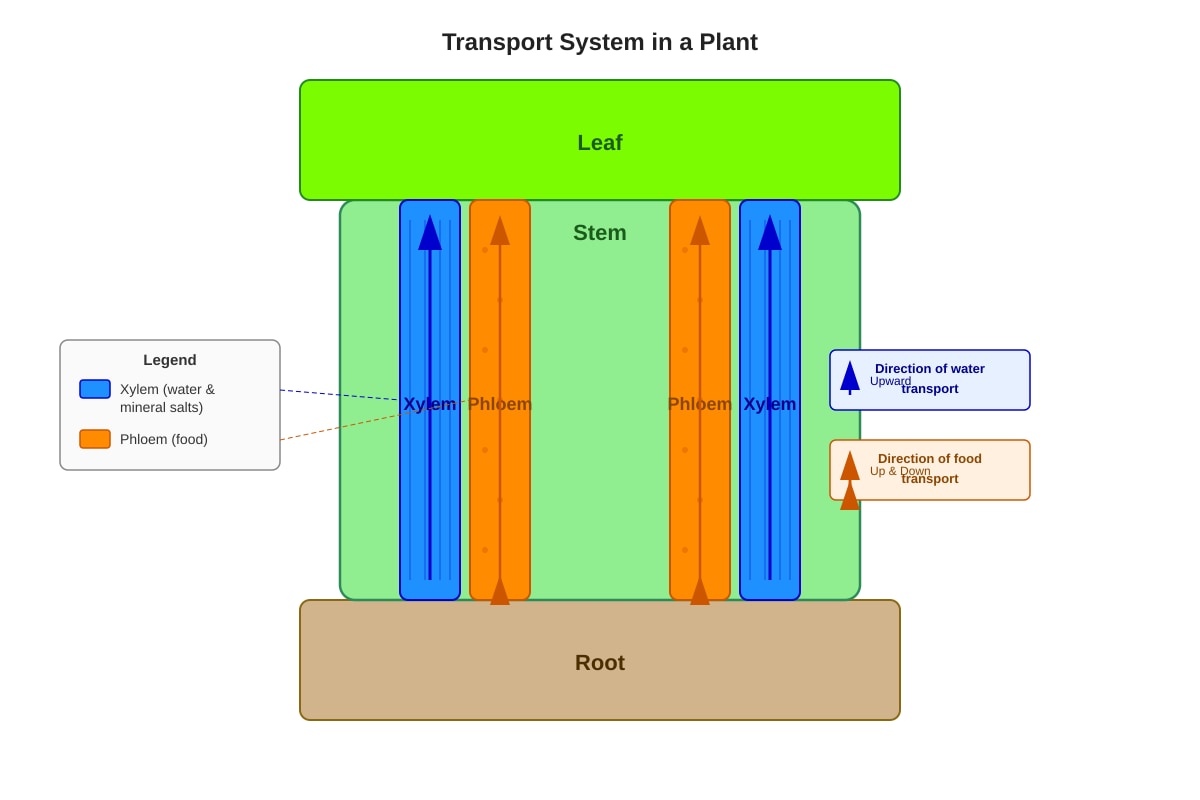
Generated diagram for Q11.
What is transported in the xylem and in which direction?
(1) Water and mineral salts, from leaves to roots
(2) Water and mineral salts, from roots to leaves
(3) Food, from leaves to roots
(4) Food, from roots to leaves
[2]
Question 12
The diagram below shows the human circulatory system.
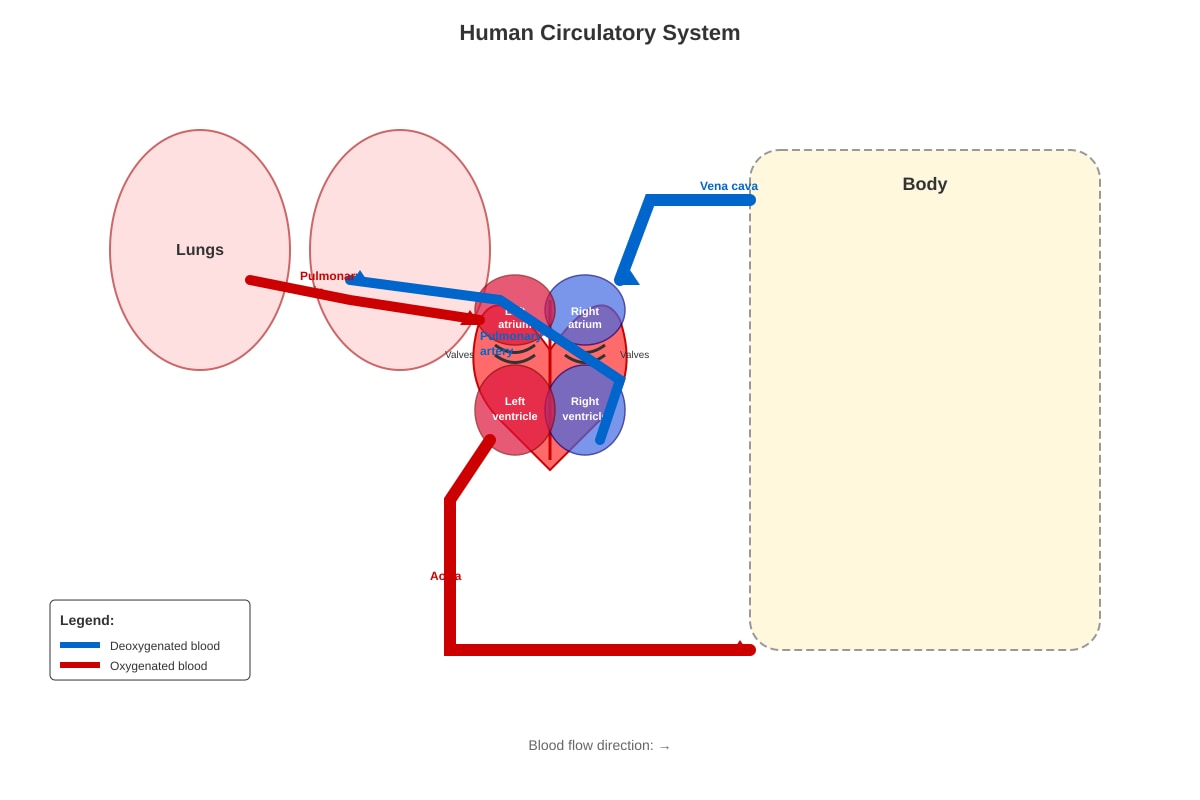
Generated diagram for Q12.
Blood in the pulmonary artery is __________.
(1) oxygenated and flowing to the lungs
(2) deoxygenated and flowing to the lungs
(3) oxygenated and flowing to the heart
(4) deoxygenated and flowing to the heart
[2]
Question 13
Which of the following shows the correct path of air during inhalation?
(1) Nose → Trachea → Bronchi → Lungs → Alveoli
(2) Nose → Bronchi → Trachea → Lungs → Alveoli
(3) Nose → Trachea → Lungs → Bronchi → Alveoli
(4) Nose → Lungs → Trachea → Bronchi → Alveoli
[2]
Question 14
The diagram below shows an electrical circuit.
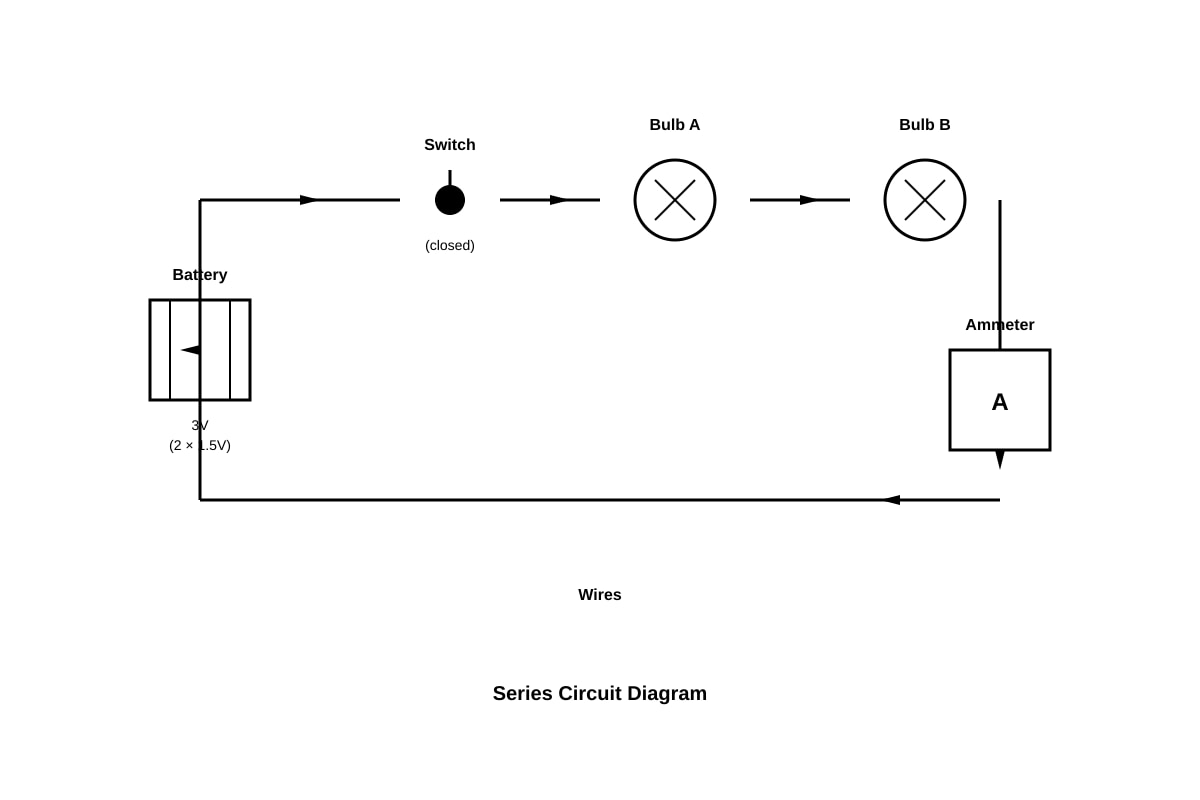
Generated diagram for Q14.
If Bulb B fuses (filament breaks), what will happen to Bulb A and the ammeter reading?
| Bulb A | Ammeter reading | |
|---|---|---|
| (1) | Lights up | Increases |
| (2) | Lights up | Decreases to zero |
| (3) | Does not light up | Decreases to zero |
| (4) | Does not light up | Remains the same |
[2]
Question 15
Three identical bulbs are connected in a circuit as shown below.
Image pending generation: diagram for Q15.
Which statement about this circuit is correct?
(1) If Bulb 1 fuses, Bulb 2 and Bulb 3 will not light up.
(2) The brightness of each bulb is the same as a single bulb connected to the same battery.
(3) The current through each bulb is the same as the current from the battery.
(4) Adding more bulbs in parallel will make each bulb dimmer.
[2]
Question 16
Which of the following materials is a conductor of electricity?
(1) Rubber
(2) Plastic
(3) Copper
(4) Wood
[2]
Question 17
The diagram below shows an electromagnet.
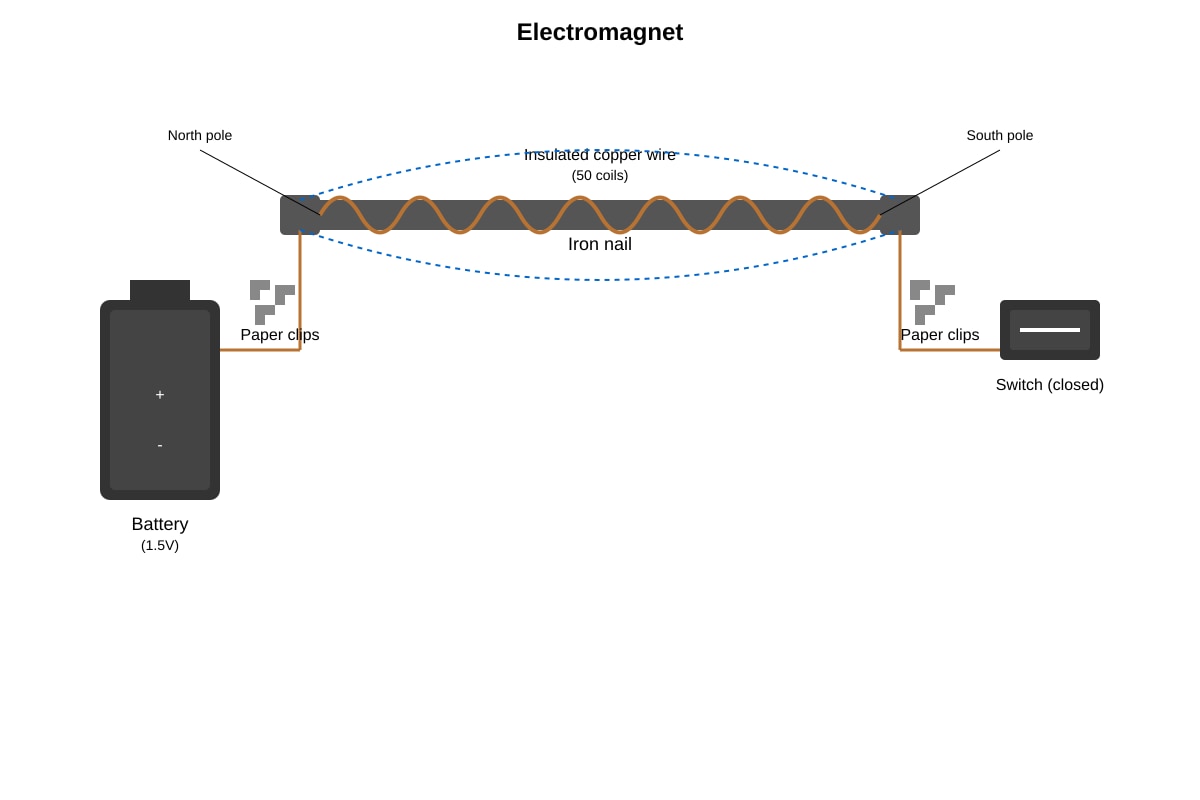
Generated diagram for Q17.
Which change will not increase the strength of the electromagnet?
(1) Increase the number of coils around the nail
(2) Use a thicker copper wire
(3) Add another battery in series
(4) Replace the iron nail with a steel nail
[2]
Question 18
Study the classification table below.
| Group A | Group B |
|---|---|
| Iron nail | Copper wire |
| Steel paper clip | Aluminium foil |
| Cobalt bar | Gold ring |
The materials are grouped based on their __________.
(1) electrical conductivity
(2) magnetic properties
(3) thermal conductivity
(4) hardness
[2]
Question 19
The diagram below shows the changes in states of matter.
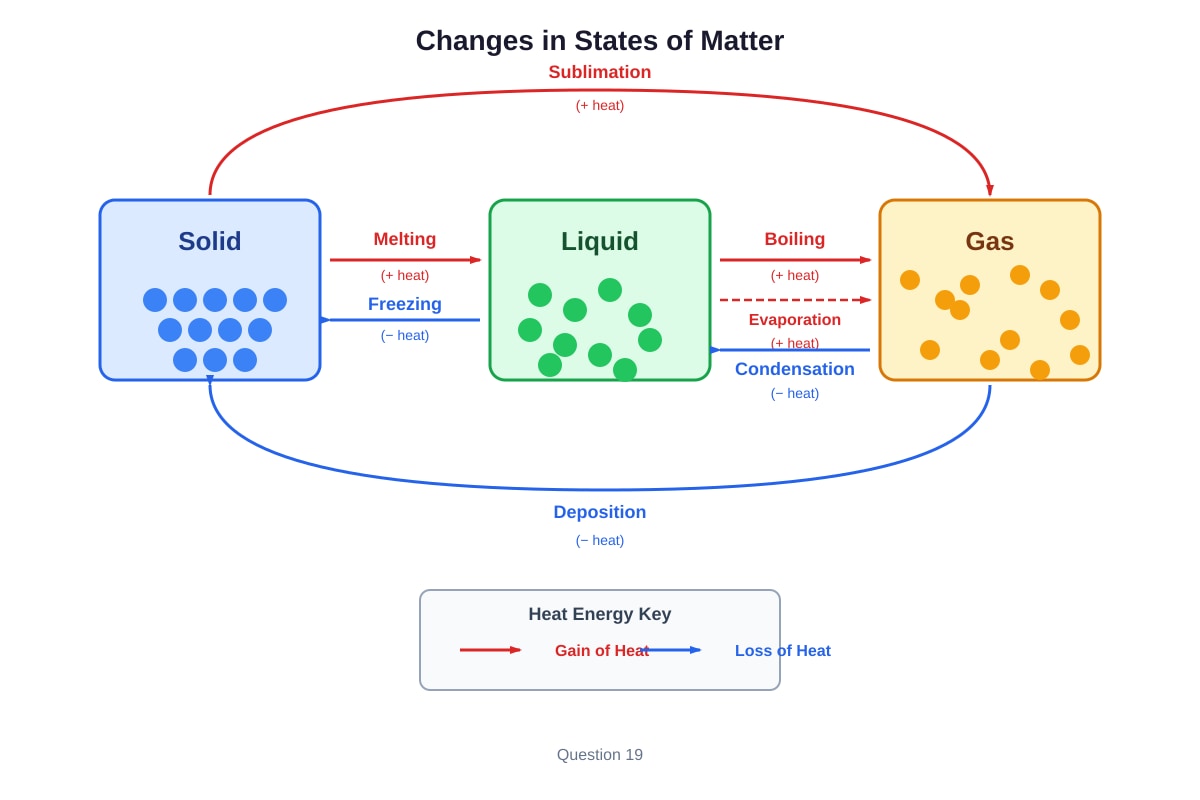
Generated diagram for Q19.
Which process involves a gain of heat and a change from liquid to gas?
(1) Freezing
(2) Condensation
(3) Boiling
(4) Melting
[2]
Question 20
Four beakers contain equal volumes of water at different temperatures. Identical ice cubes are added to each beaker.
| Beaker | Water Temperature (°C) |
|---|---|
| A | 10 |
| B | 30 |
| C | 50 |
| D | 80 |
In which beaker will the ice cube melt the fastest?
(1) A
(2) B
(3) C
(4) D
[2]
Question 21
The diagram below shows a shadow formed on a screen.
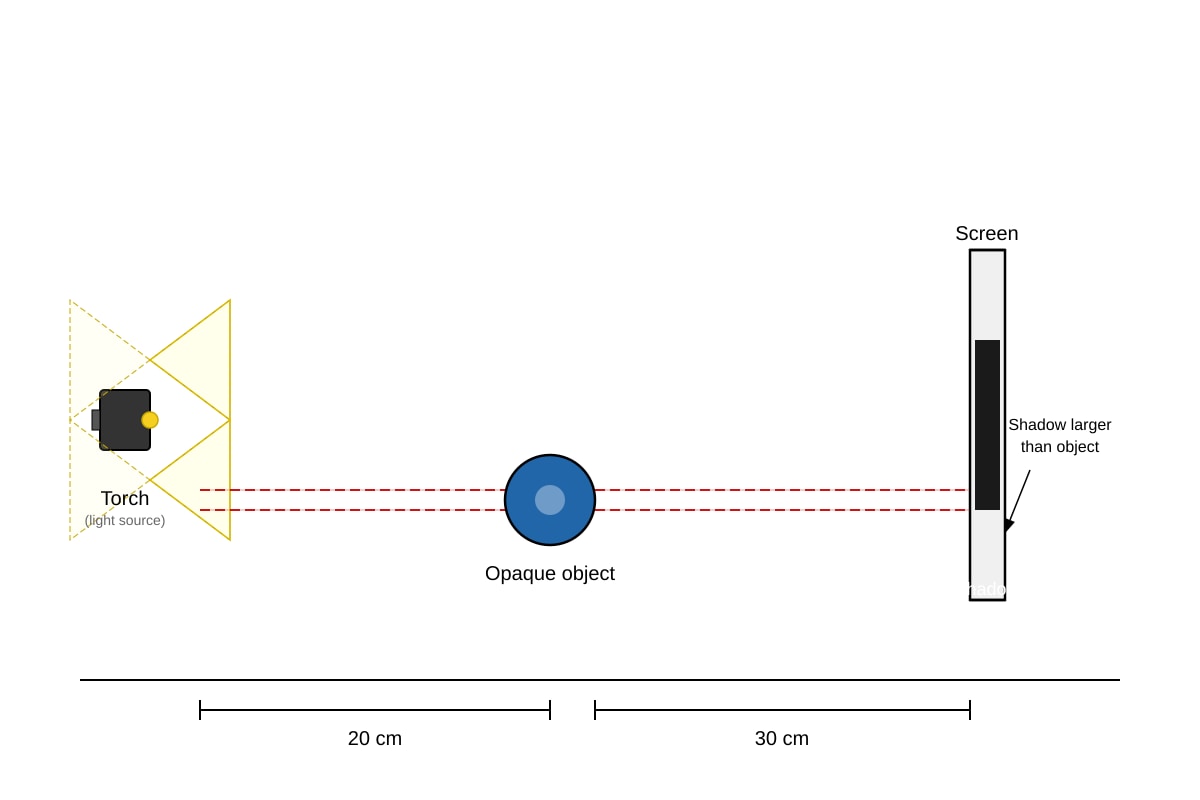
Generated diagram for Q21.
To make the shadow smaller, without moving the screen, the object should be moved __________.
(1) closer to the torch
(2) closer to the screen
(3) further from the torch
(4) further from the screen
[2]
Question 22
Which of the following is a non-renewable energy source?
(1) Solar energy
(2) Wind energy
(3) Coal
(4) Hydroelectric energy
[2]
Question 23
The diagram below shows a lever system.
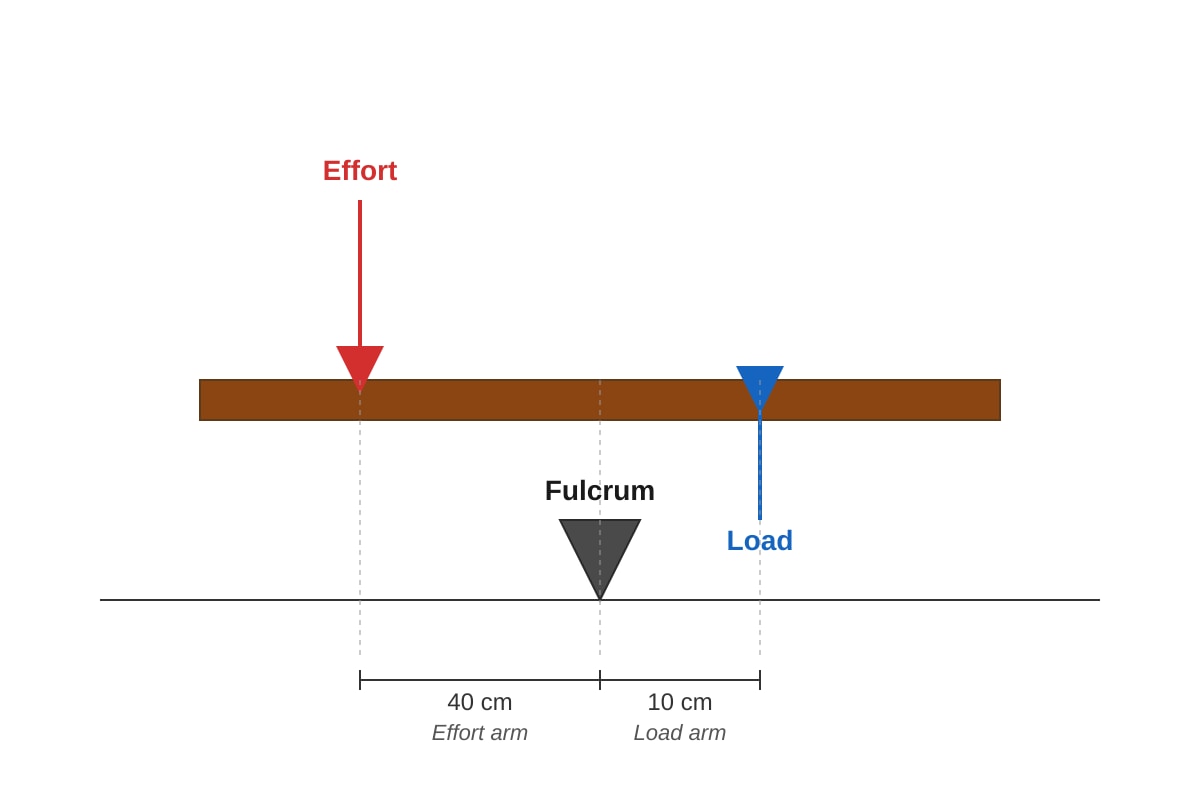
Generated diagram for Q23.
If the load is 20 N, what is the minimum effort needed to lift the load?
(1) 5 N
(2) 10 N
(3) 20 N
(4) 80 N
[2]
Question 24
Which of the following forces is a non-contact force?
(1) Friction
(2) Air resistance
(3) Magnetic force
(4) Push
[2]
Question 25
A ball is thrown vertically upwards. Which of the following statements is correct about the forces acting on the ball as it moves upwards? (Ignore air resistance.)
(1) Only gravity acts on the ball, pulling it downwards.
(2) The throwing force continues to act on the ball upwards.
(3) Both gravity and the throwing force act on the ball.
(4) No forces act on the ball as it moves upwards.
[2]
Question 26
The diagram below shows a spring balance being used to measure the weight of an object.
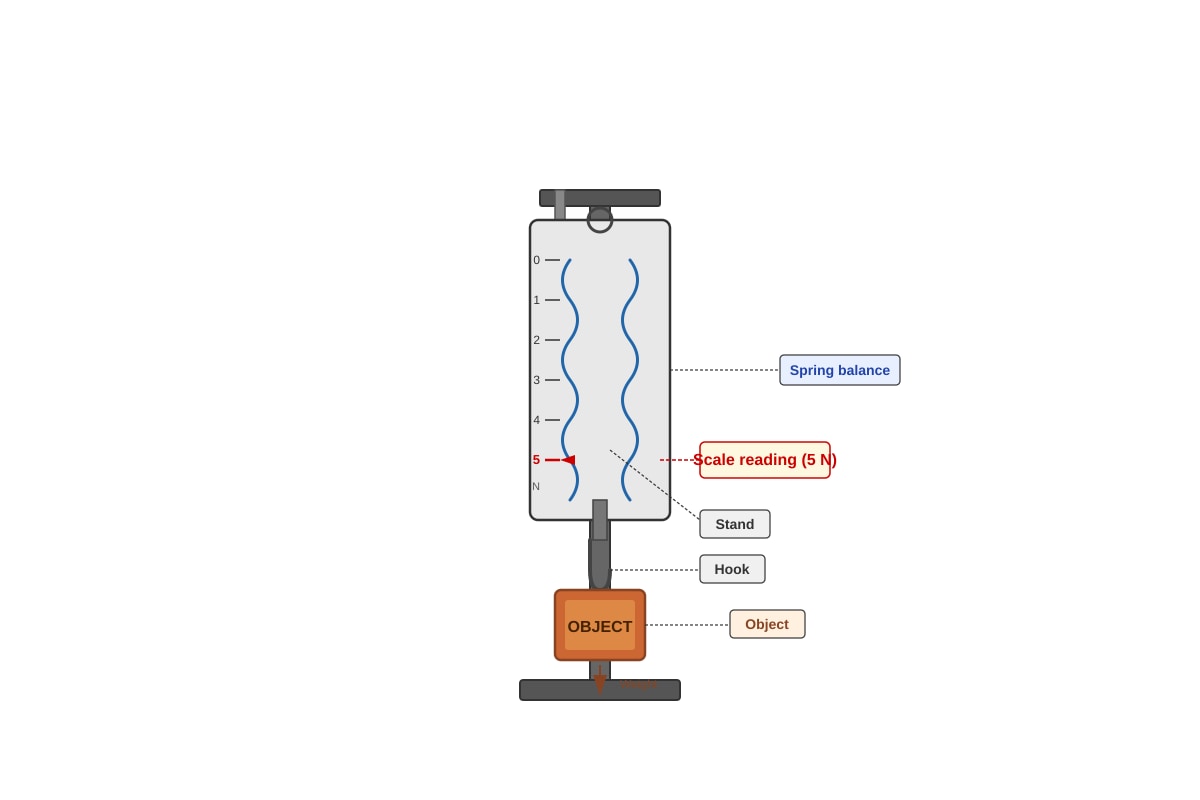
Generated diagram for Q26.
What is the mass of the object? (Take gravitational field strength = 10 N/kg)
(1) 0.5 kg
(2) 5 kg
(3) 50 kg
(4) 500 kg
[2]
Question 27
Which of the following shows the correct energy conversion when a battery-operated torch is switched on?
(1) Electrical energy → Light energy + Heat energy
(2) Chemical energy → Electrical energy → Light energy + Heat energy
(3) Chemical energy → Light energy + Heat energy
(4) Electrical energy → Chemical energy → Light energy + Heat energy
[2]
Question 28
The diagram below shows a food chain.
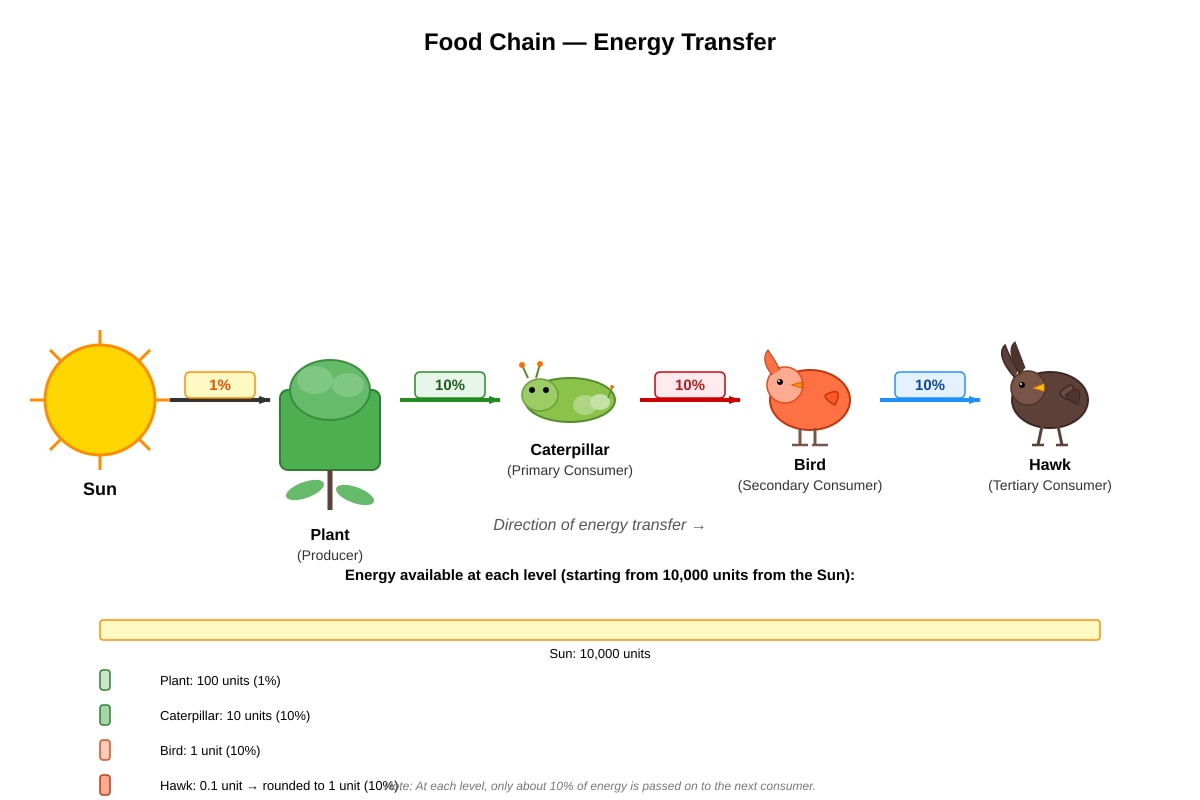
Generated diagram for Q28.
If the plant absorbs 10,000 units of energy from the Sun, how much energy is transferred to the hawk?
(1) 1 unit
(2) 10 units
(3) 100 units
(4) 1000 units
[2]
SECTION B (44 marks)
Write your answers in the spaces provided. The number of marks is given in brackets [ ] at the end of each question or part question.
Question 29
The diagram below shows two cells, Cell A and Cell B.
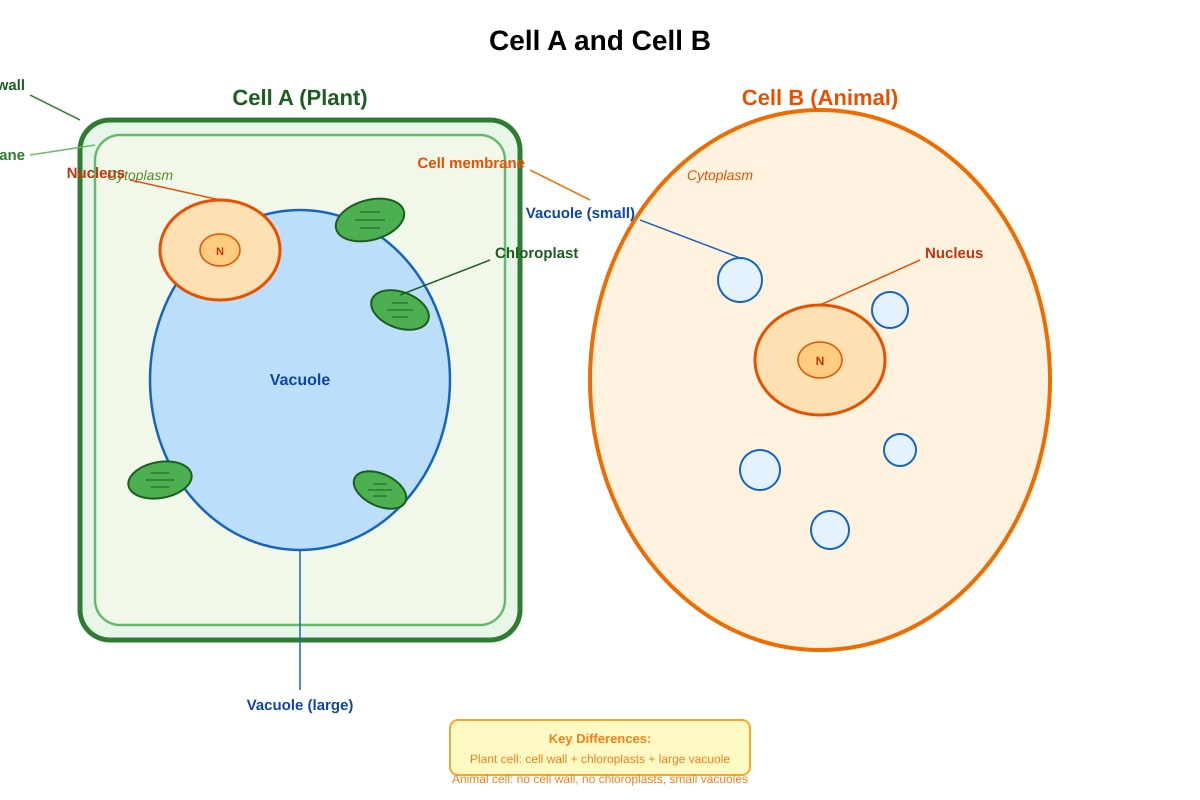
Generated diagram for Q29.
(a) Identify Cell A and Cell B.
Cell A: ________________________
Cell B: ________________________
[1]
(b) State one function of the nucleus.
[1]
(c) State two structures present in Cell A but not in Cell B.
[2]
(d) Explain why chloroplasts are found in Cell A but not in Cell B.
[2]
Question 30
The diagram below shows the reproductive parts of a flower.
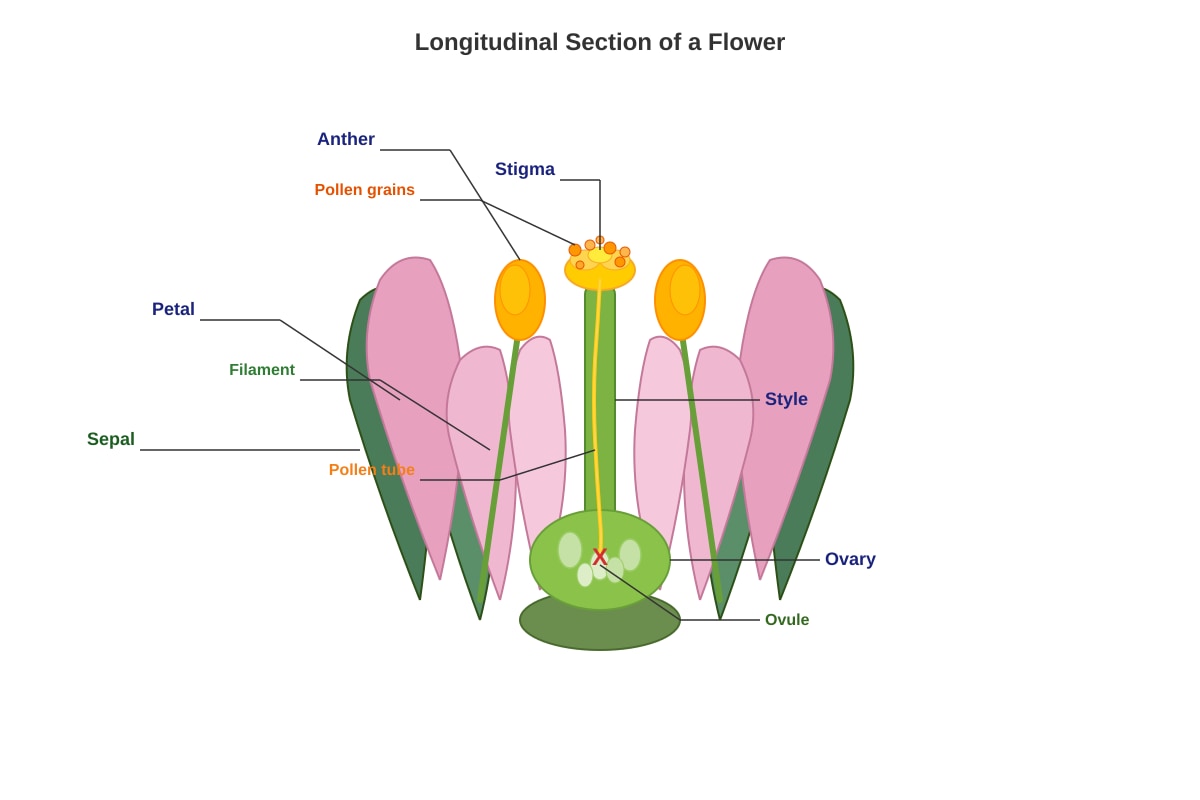
Generated diagram for Q30.
(a) Name the part labelled X (the swollen base of the pistil that contains ovules).
[1]
(b) What is the function of the anther?
[1]
(c) Describe the process of pollination.
[2]
(d) After fertilisation, the ovule develops into a __________ and the ovary develops into a __________.
[2]
(e) State one way seeds can be dispersed.
[1]
Question 31
The diagram below shows the human digestive system.
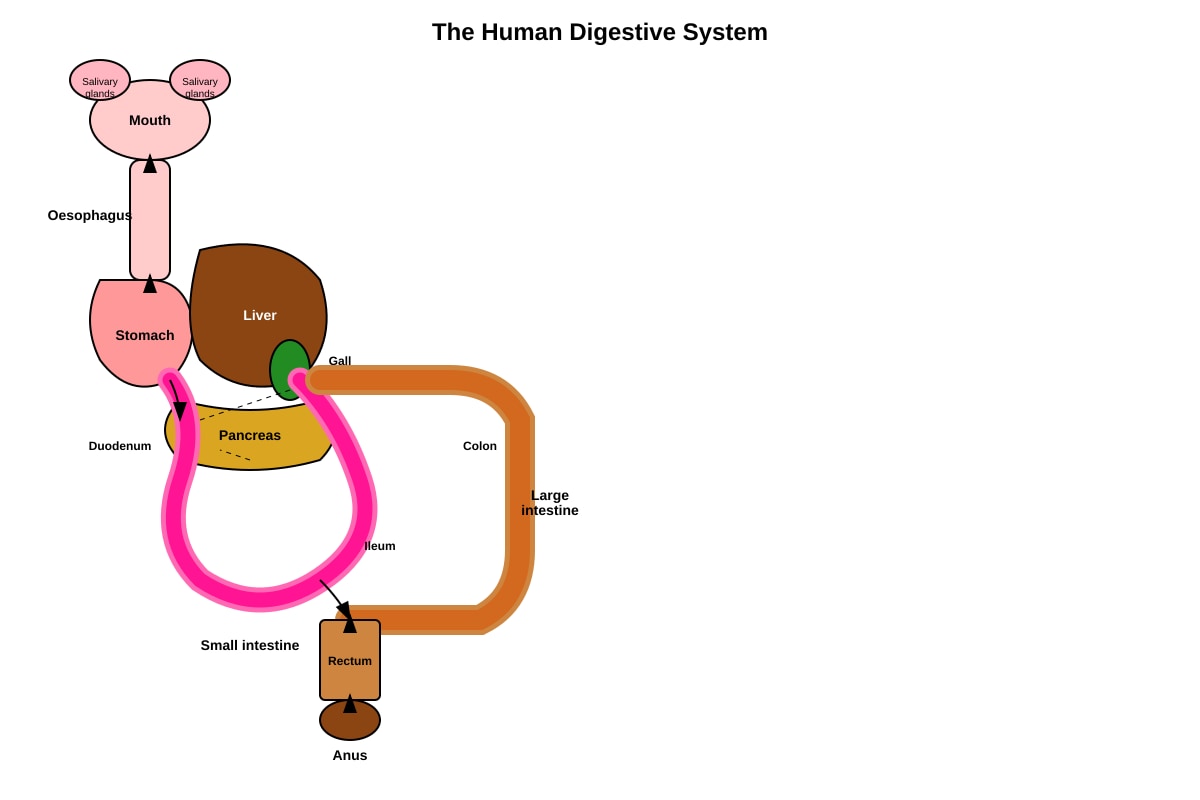
Generated diagram for Q31.
(a) In which organ does most absorption of digested food take place?
[1]
(b) State the function of the large intestine.
[1]
(c) The table below shows the action of digestive juices on different food substances. Complete the table.
| Digestive Juice | Food Substance Acted Upon | Product Formed |
|---|---|---|
| Saliva | Starch | _______________ |
| Gastric juice | _______________ | Peptides |
| Pancreatic juice | Fats | _______________ |
[3]
(d) Explain why digestion is important for the body.
[2]
Question 32
The diagram below shows the water cycle.
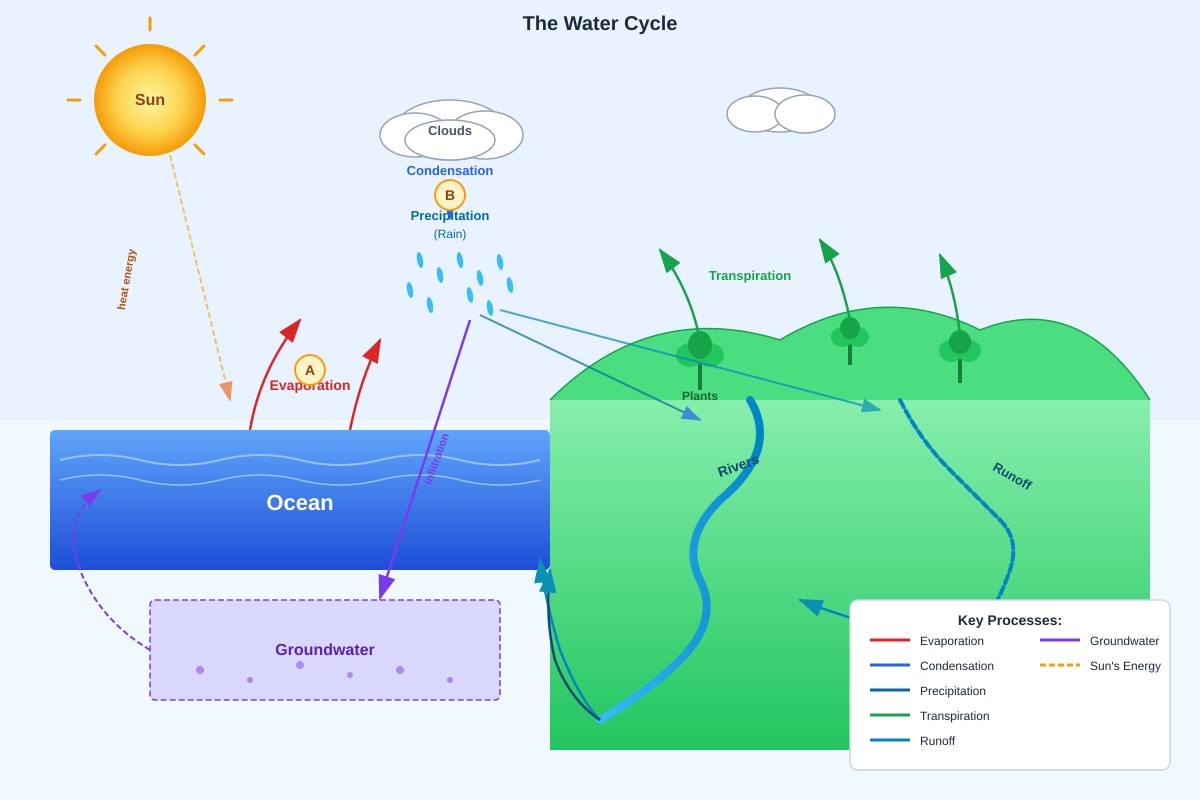
Generated diagram for Q32.
(a) Name the process at A (water vapour rising from the ocean).
[1]
(b) Name the process at B (water vapour cooling to form clouds).
[1]
(c) Explain how deforestation (cutting down trees) can affect the water cycle.
[2]
(d) State two factors that increase the rate of evaporation.
[2]
Question 33
The diagram below shows the human circulatory system.
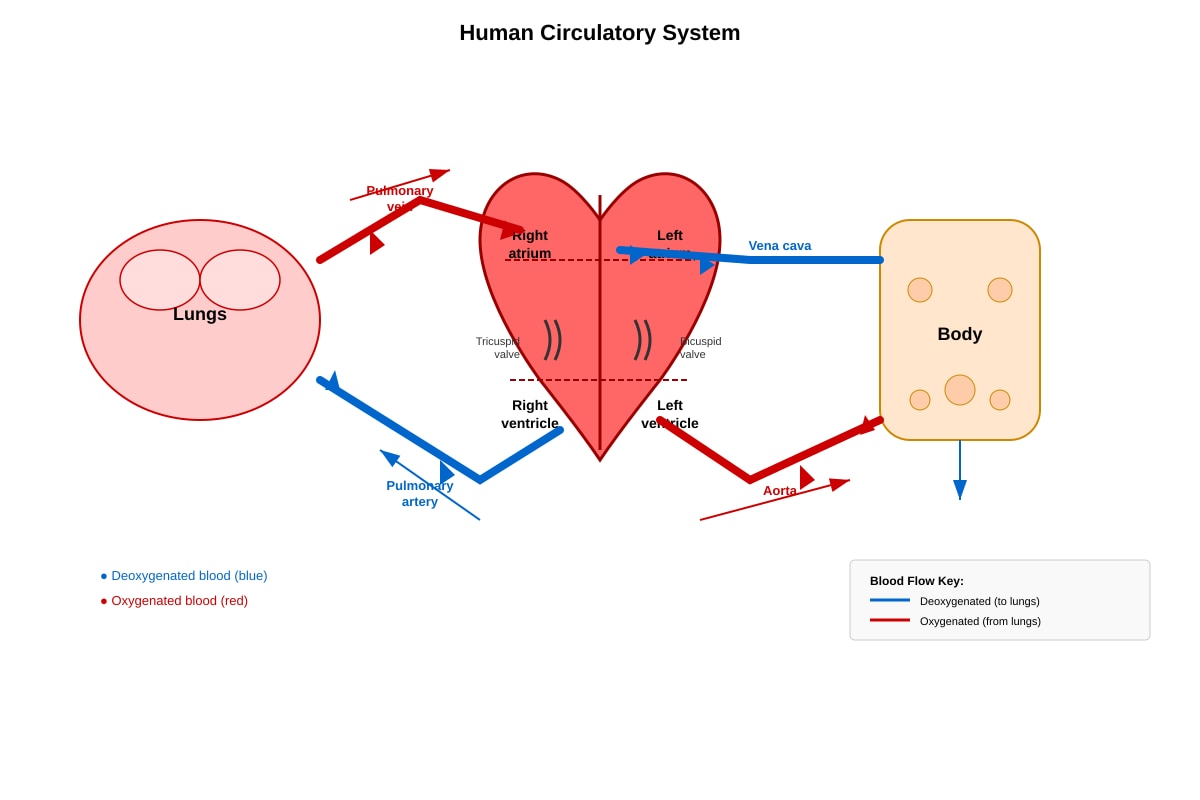
Generated diagram for Q33.
(a) Blood vessel X carries deoxygenated blood from the heart to the lungs. Name blood vessel X.
[1]
(b) Blood vessel Y carries oxygenated blood from the lungs to the heart. Name blood vessel Y.
[1]
(c) The heart acts as a pump. Explain why the left ventricle has a thicker muscular wall than the right ventricle.
[2]
(d) State one function of the valves in the heart.
[1]
Question 34
The diagram below shows an electrical circuit with three identical bulbs.
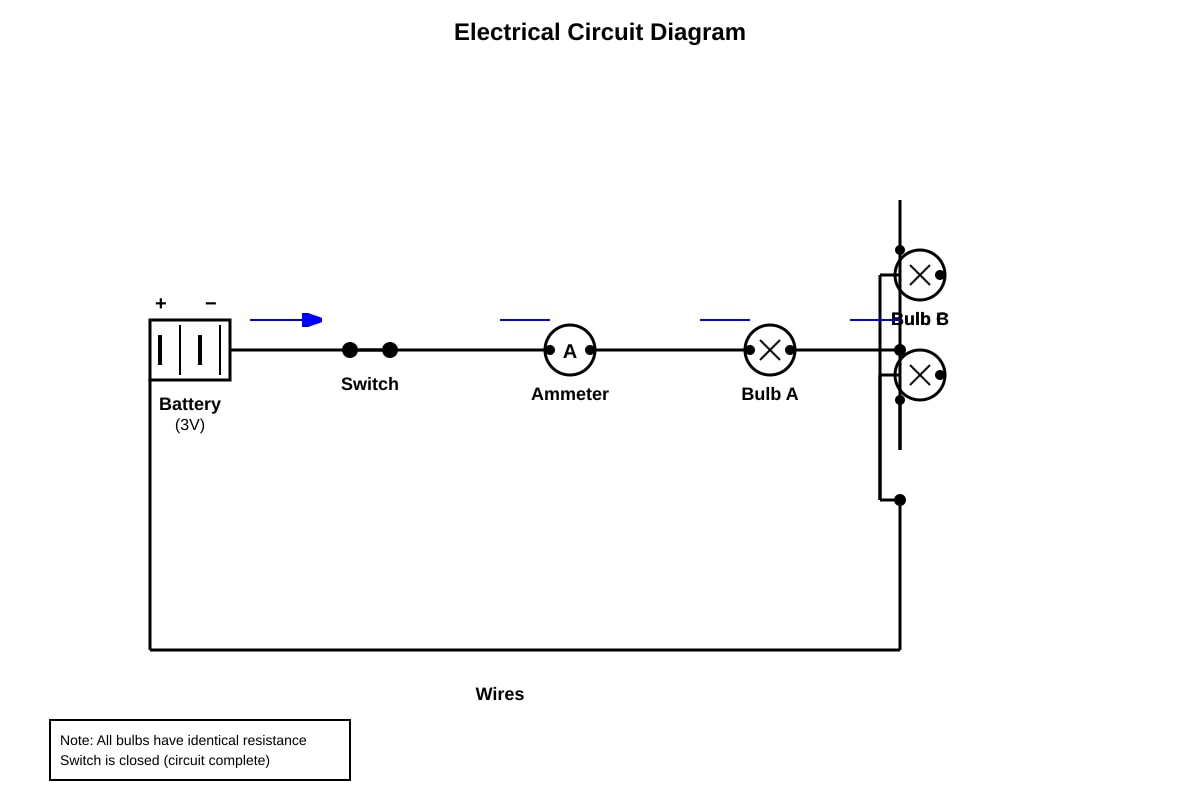
Generated diagram for Q34.
(a) Are the bulbs connected in series or in parallel?
Bulb A and the combination of B & C: ________________________
Bulb B and Bulb C: ________________________
[2]
(b) If Bulb B fuses, what happens to the brightness of Bulb A and Bulb C?
Bulb A: ________________________
Bulb C: ________________________
[2]
(c) State one advantage of connecting bulbs in parallel in household lighting.
[1]
Question 35
The diagram below shows a set-up to investigate the strength of an electromagnet.
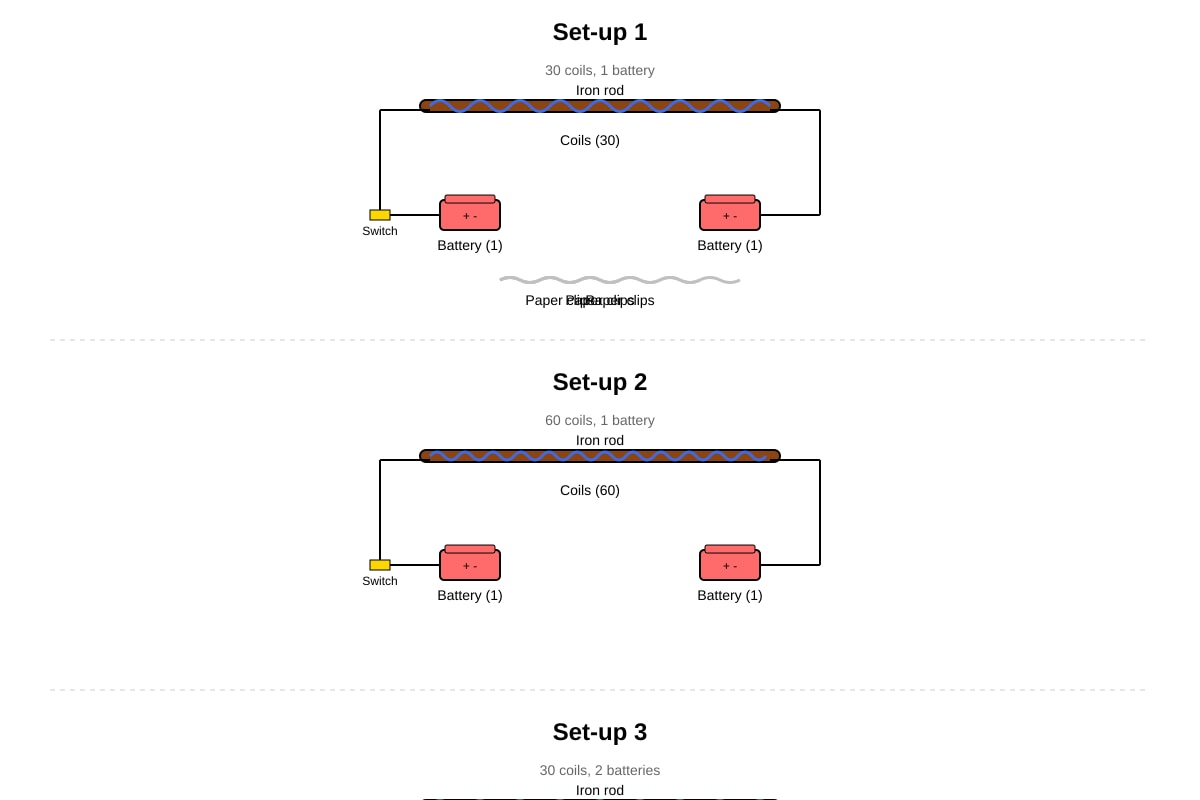
Generated experimental_setup for Q35.
The table below shows the results.
| Set-up | Number of Coils | Number of Batteries | Number of Paper Clips Attracted |
|---|---|---|---|
| 1 | 30 | 1 | 5 |
| 2 | 60 | 1 | 10 |
| 3 | 30 | 2 | 9 |
(a) Based on the results, state the relationship between the number of coils and the strength of the electromagnet.
[2]
(b) Based on the results, state the relationship between the number of batteries and the strength of the electromagnet.
[2]
(c) Suggest one other way to increase the strength of the electromagnet, besides changing the number of coils or batteries.
[1]
Question 36
The diagram below shows three objects, A, B, and C, placed on a balance.
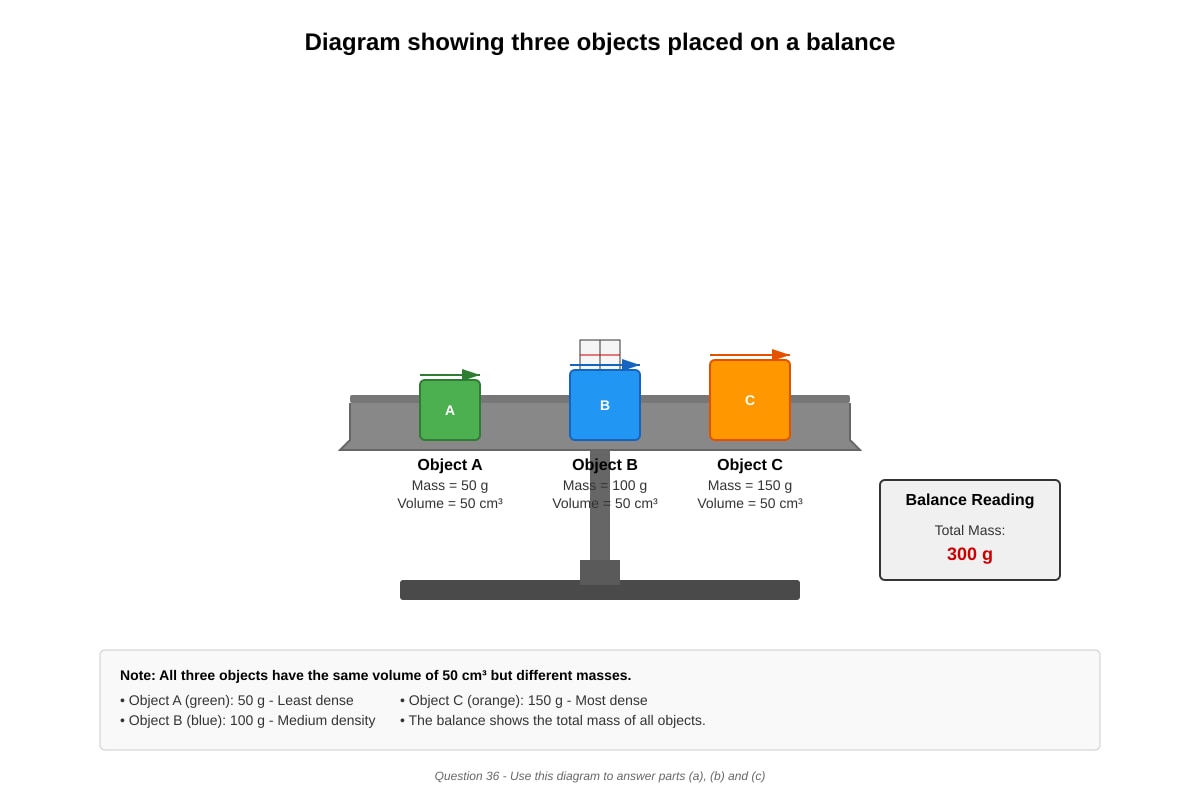
Generated diagram for Q36.
(a) Calculate the density of Object B. (Density = Mass ÷ Volume)
[2]
(b) The three objects are placed in a tank of water (density = 1 g/cm³). Which object(s) will float?
[1]
(c) Explain your answer in (b).
[2]
Question 37
The diagram below shows a ray of light hitting a plane mirror.
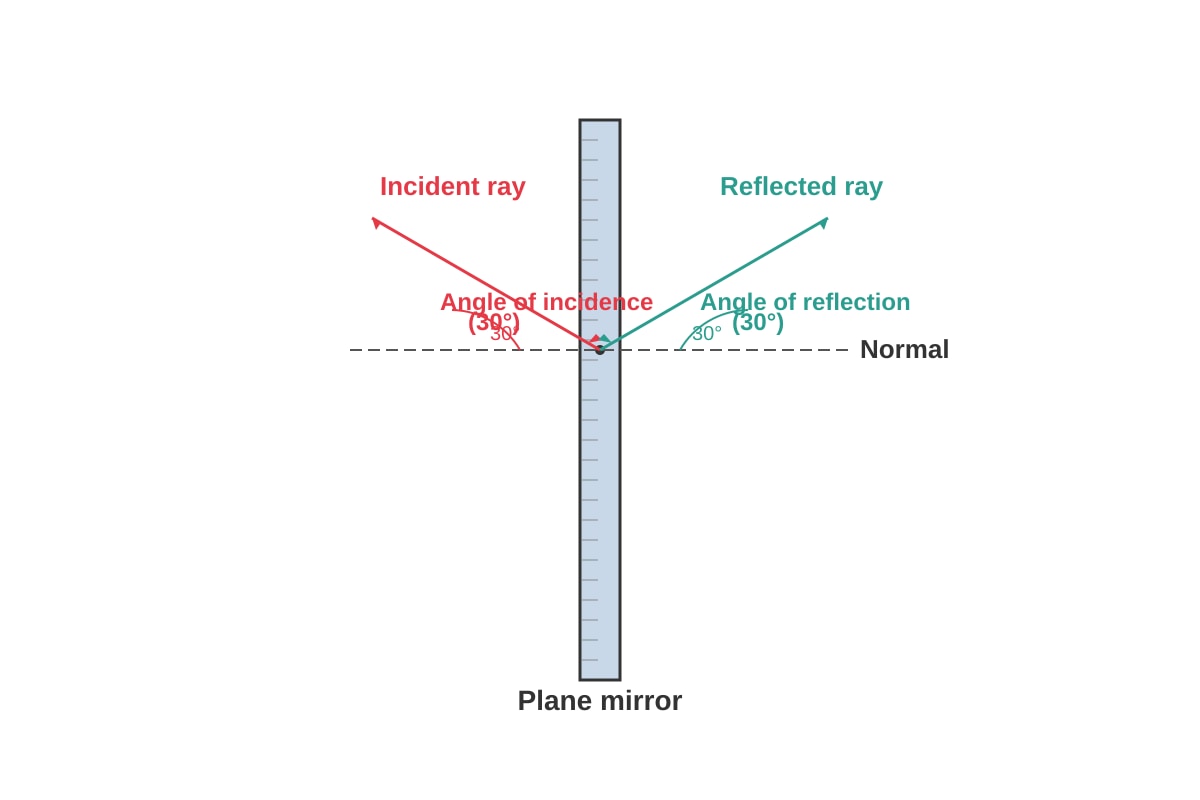
Generated diagram for Q37.
(a) What is the angle of reflection?
[1]
(b) State the law of reflection.
[1]
(c) If the mirror is rotated by 10° clockwise (while the incident ray stays the same), what is the new angle of reflection?
[2]
Question 38
The diagram below shows a food web in a pond community.
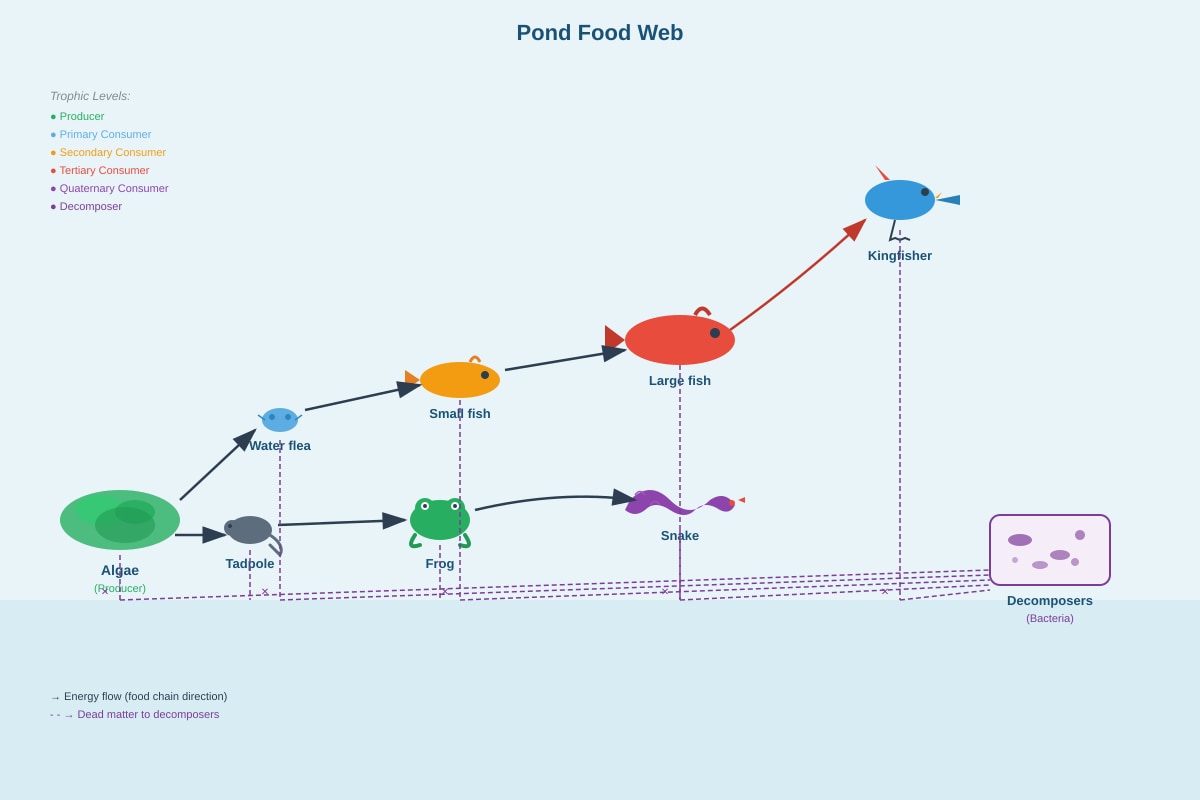
Generated diagram for Q38.
(a) How many food chains are there in this food web?
[1]
(b) Write out one food chain from this food web with four organisms.
[1]
(c) If all the water fleas are removed, explain what will happen to the population of small fish and algae.
Small fish: ____________________________________________________________________
Algae: _______________________________________________________________________
[2]
(d) State the role of decomposers in this community.
[1]
Question 39
A student conducted an experiment to find out how the height of a ramp affects the distance a toy car travels after leaving the ramp.
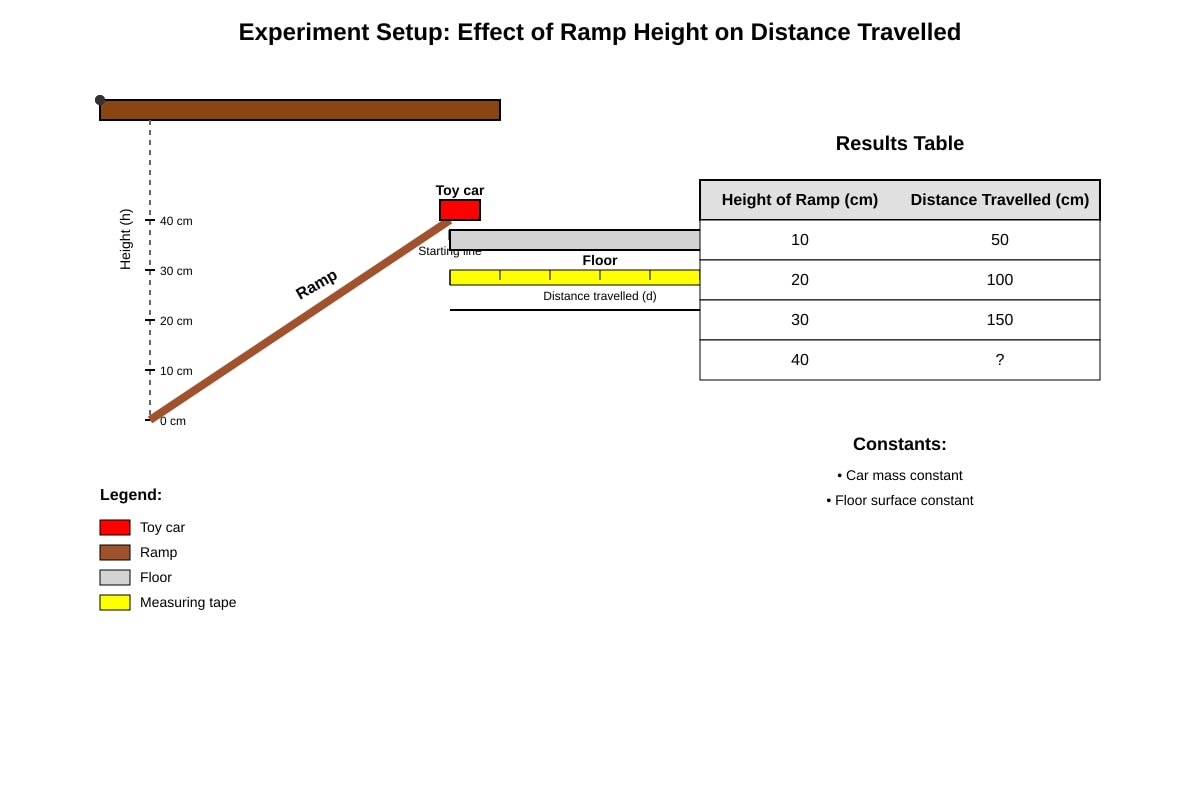
Generated experimental_setup for Q39.
The results are shown below.
| Height of Ramp (cm) | Distance Travelled (cm) |
|---|---|
| 10 | 50 |
| 20 | 100 |
| 30 | 150 |
| 40 | 200 |
(a) What is the aim of this experiment?
[1]
(b) What is the independent variable (changed variable)?
[1]
(c) What is the dependent variable (measured variable)?
[1]
(d) State one variable that must be kept constant (controlled variable) for a fair test.
[1]
(e) Based on the results, what is the relationship between the height of the ramp and the distance travelled?
[1]
(f) Predict the distance travelled if the ramp height is 50 cm.
[1]
Question 40
The diagram below shows a lever system used to lift a rock.
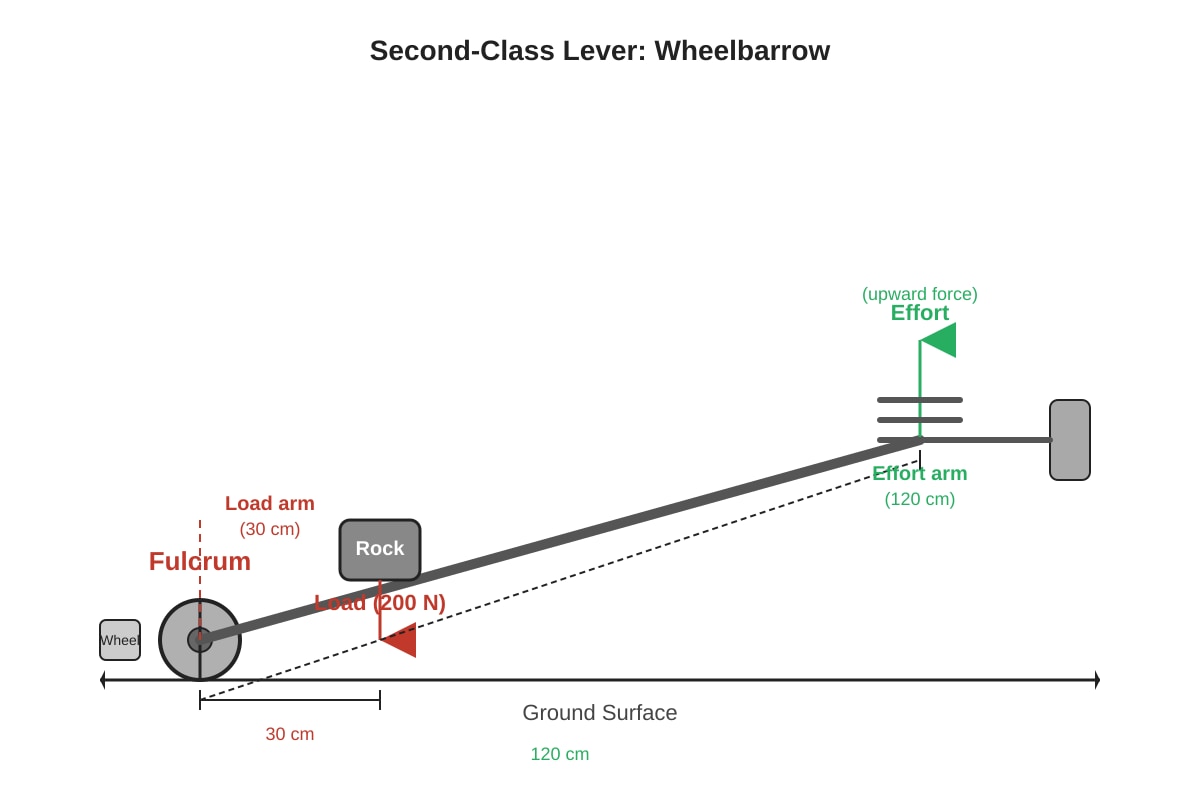
Generated diagram for Q40.
(a) What class of lever is this? (First, Second, or Third class)
[1]
(b) Calculate the minimum effort needed to lift the rock. (Use the principle of moments: Effort × Effort arm = Load × Load arm)
[2]
(c) If the effort is applied at a point closer to the fulcrum, what happens to the effort needed?
[1]
(d) Give one example of a first-class lever in daily life.
[1]
END OF PAPER
Answers
TuitionGoWhere Practice Paper - Science Primary 5 (SA2) - Answer Key
Subject: Science
Level: Primary 5
Paper: SA2
Total Marks: 100
SECTION A (56 marks)
Question 1
Answer: (3)
Explanation: All living things respond to changes in their surroundings (sensitivity). This is one of the seven life processes.
- (1) is incorrect: Only plants (producers) make their own food; animals and fungi cannot.
- (2) is incorrect: Reproduction methods vary (live birth, eggs, spores, budding).
- (4) is incorrect: Some microorganisms (anaerobic bacteria) do not need oxygen.
Question 2
Answer: (3)
Explanation: Chloroplasts contain chlorophyll, the green pigment that traps light energy for photosynthesis. The diagram shows Part X pointing to the chloroplast.
- Nucleus controls cell activities.
- Cytoplasm is where most cellular activities occur.
- Vacuole stores water and substances.
Question 3
Answer: (2)
Explanation: Mushroom is a fungus, not a plant. Fungi do not photosynthesise and obtain nutrients by decomposition. Ferns, mosses, and algae are non-flowering plants.
Question 4
Answer: (2)
Explanation:
- Bala is correct: Yeast is a single-celled fungus (microorganism).
- Cindy is correct: Bacteria are microscopic and require a microscope to be seen.
- Ali is incorrect: Many microorganisms are beneficial (e.g., yeast in bread, bacteria
<stage3_exam_answers_md>
TuitionGoWhere Practice Paper - Science Primary 5 (Answer Key)
SECTION A (56 marks)
| Question | Answer | Explanation |
|---|---|---|
| 1 | (3) | All living things respond to changes in their surroundings (sensitivity). Not all make their own food (only plants), reproduce by laying eggs, or need oxygen (some anaerobes). |
| 2 | (3) | Chloroplasts contain chlorophyll and trap light energy for photosynthesis. |
| 3 | (2) | Mushroom is a fungus, not a plant. Fern, moss, and algae are non-flowering plants. |
| 4 | (2) | Bala: Yeast is a microorganism (fungus). Cindy: Bacteria are microscopic. Ali is wrong (some microorganisms are useful). Devi is wrong (mould is a fungus, not bacteria). |
| 5 | (3) | After fertilisation, the ovary develops into fruit and ovules develop into seeds. |
| 6 | (2) | Correct sequence: Ovulation → Fertilisation → Implantation → Development. |
| 7 | (2) | Sperm has a tail (flagellum) for swimming; egg is non-motile. Egg is larger. Sperm produced in large numbers; egg usually one per month. Egg contains yolk (stored food); sperm has minimal cytoplasm. |
| 8 | (1) | Grasshoppers are primary consumers eating grass. If grasshoppers die, grass (producer) population increases due to reduced herbivory. |
| 9 | (3) | Arrow from clouds to ground represents precipitation (rain, snow, etc.). |
| 10 | (3) | Higher humidity decreases evaporation rate (air already saturated with water vapour). |
| 11 | (2) | Xylem transports water and mineral salts from roots to leaves (upward). |
| 12 | (2) | Pulmonary artery carries deoxygenated blood from right ventricle to lungs. |
| 13 | (1) | Air path: Nose → Trachea → Bronchi → Bronchioles → Alveoli (in lungs). |
| 14 | (3) | Series circuit: if one bulb fuses, circuit breaks → both bulbs off, current drops to zero. |
| 15 | (2) | In parallel, each bulb gets full battery voltage → same brightness as single bulb. If one fuses, others stay lit. Current splits; total current from battery increases with more bulbs. |
| 16 | (3) | Copper is a good electrical conductor. Rubber, plastic, wood are insulators. |
| 17 | (4) | Steel nail retains magnetism (permanent magnet) but does not increase electromagnet strength as effectively as soft iron. More coils, more voltage (series battery), thicker wire (less resistance, more current) all increase strength. |
| 18 | (2) | Group A: Iron, Steel, Cobalt → magnetic materials (ferromagnetic). Group B: Copper, Aluminium, Gold → non-magnetic. |
| 19 | (3) | Boiling: liquid → gas with heat gain. Freezing and condensation release heat. Melting is solid → liquid. |
| 20 | (4) | Highest temperature difference (80°C vs 0°C ice) → fastest heat transfer → fastest melting. |
| 21 | (2) | Moving object closer to screen reduces shadow size (less divergence of light rays before hitting screen). |
| 22 | (3) | Coal is a fossil fuel (non-renewable). Solar, wind, hydro are renewable. |
| 23 | (1) | Principle of moments: Effort × Effort arm = Load × Load arm → Effort × 40 = 20 × 10 → Effort = 5 N. |
| 24 | (3) | Magnetic force acts at a distance (non-contact). Friction, air resistance, push require contact. |
| 25 | (1) | After release, only gravity (weight) acts downwards. Throwing force ceases once contact is lost. |
| 26 | (1) | Weight = mass × g → 5 N = mass × 10 N/kg → mass = 0.5 kg. |
| 27 | (2) | Battery stores chemical energy → converted to electrical energy → converted to light + heat in bulb. |
| 28 | (3) | See explanation below. |
Question 28
Diagram: A cup of hot tea at 80°C placed in a room at 28°C. Graph shows temperature of tea vs time: curve decreasing from 80°C, approaching 28°C asymptotically.
Question: Which statement about the heat transfer is correct?
(1) Heat is transferred from the room to the tea.
(2) The tea loses heat until it reaches 0°C.
(3) Heat is transferred from the tea to the room until both reach the same temperature.
(4) The room temperature increases significantly as the tea cools.
Answer: (3)
Heat flows from hotter object (tea) to cooler surroundings (room) until thermal equilibrium (same temperature). Room temperature rises negligibly due to large volume.
SECTION B (44 marks)
Question 29 [4]
Diagram: Plant cell and animal cell side by side. Structures labelled: Nucleus, Cytoplasm, Cell membrane, Cell wall (plant only), Chloroplast (plant only), Large vacuole (plant only), Small vacuoles (animal).
(a) Identify two structures present in the plant cell but absent in the animal cell.
Answer: Cell wall, chloroplasts, large central vacuole (any two). [2]
(b) State the function of the nucleus.
Answer: Controls all cellular activities / contains genetic material (DNA) that determines characteristics. [1]
(c) Why are chloroplasts found only in plant cells?
Answer: Plants photosynthesise (make their own food); animals obtain food by eating. [1]
Question 30 [3]
Diagram: Flower longitudinal section. Parts labelled: Stigma, Style, Ovary, Ovule, Anther, Filament, Petal, Sepal.
(a) Name the part that produces pollen grains.
Answer: Anther. [1]
(b) After pollination, pollen tube grows down the style to the ovary. What is the function of the pollen tube?
Answer: To transport the male nucleus (sperm cell) to the ovule for fertilisation. [1]
(c) The ovule develops into the ________ after fertilisation.
Answer: Seed. [1]
Question 31 [4]
Diagram: Human respiratory system. Labels: Trachea, Bronchus, Bronchioles, Alveoli, Rib cage, Diaphragm, Intercostal muscles.
(a) Name the tiny air sacs where gaseous exchange occurs.
Answer: Alveoli. [1]
(b) State two structural adaptations of the alveoli for efficient gaseous exchange.
Answer:
- Thin walls (one cell thick) for short diffusion distance.
- Large surface area (many alveoli) / moist lining for gas dissolution / rich blood supply (capillaries). (Any two) [2]
(c) When we inhale, the diaphragm ________ (contracts/relaxes) and moves ________ (upwards/downwards).
Answer: Contracts, downwards. [1]
Question 32 [4]
Diagram: Food chain: Grass → Grasshopper → Frog → Snake → Hawk. Pyramid of numbers and pyramid of biomass shown.
(a) Identify the producer in this food chain.
Answer: Grass. [1]
(b) If all frogs are removed, what happens to the grasshopper population? Explain.
Answer: Grasshopper population increases because their predator (frog) is gone. [1]
(c) Energy is lost at each trophic level. State two ways energy is lost.
Answer: Heat loss (respiration), waste (faeces/urine), uneaten parts, movement. (Any two) [2]
Question 33 [3]
Diagram: Water cycle with processes labelled A, B, C, D. A: Evaporation, B: Condensation, C: Precipitation, D: Collection/Runoff.
(a) Name process B.
Answer: Condensation. [1]
(b) During process B, water vapour ________ (gains/loses) heat and changes from ________ to ________.
Answer: Loses, gas, liquid. [1]
(c) The main source of energy driving the water cycle is the ________.
Answer: Sun. [1]
Question 34 [4]
Diagram: Cross-section of stem showing vascular bundles. Xylem and phloem labelled.
(a) Name the two types of transport tissues in plants.
Answer: Xylem and phloem. [1]
(b) Complete the table:
| Tissue | Substances transported | Direction of transport |
|---|---|---|
| Xylem | Water and mineral salts | Roots to leaves (upward) |
| Phloem | Food (sugar/sucrose) | Leaves to all parts (bidirectional) |
[2]
(c) What happens to a plant if its phloem is damaged?
Answer: Food cannot be transported from leaves to roots/storage organs → roots starve → plant dies. [1]
Question 35 [4]
Diagram: Human heart (simplified). Four chambers labelled. Arrows show blood flow.
(a) Name the chamber that receives deoxygenated blood from the body.
Answer: Right atrium. [1]
(b) Blood leaving the left ventricle enters which blood vessel?
Answer: Aorta. [1]
(c) Why is the wall of the left ventricle thicker than the right ventricle?
Answer: Left ventricle pumps blood to the whole body (high pressure needed); right ventricle pumps only to lungs (lower pressure). [1]
(d) Valves are present in the heart. State their function.
Answer: Prevent backflow of blood / ensure one-way flow. [1]
Question 36 [4]
Diagram: Series circuit with battery, switch, two bulbs (A and B), ammeter. Parallel circuit with same components but bulbs on separate branches.
(a) In the series circuit, if Bulb A is brighter than Bulb B, what can you conclude?
Answer: Bulbs are not identical (different resistance/filament thickness). In series, current is same; brightness depends on resistance (P=I²R). [1]
(b) In the parallel circuit, both bulbs light up with equal brightness. Explain why.
Answer: Each bulb receives the full voltage of the battery; identical bulbs → same current → same brightness. [1]
(c) State one advantage of connecting bulbs in parallel in household lighting.
Answer: If one bulb fuses, others remain lit / each bulb can be switched independently / all get full voltage. [1]
(d) The diagram shows an ammeter in the series circuit. Where should the ammeter be placed to measure the total current in the parallel circuit?
Answer: In the main wire before the current splits (in series with the battery). [1]
Question 37 [4]
Diagram: Electromagnet picking up paper clips. Variables: Number of coils, Battery voltage, Core material.
(a) The strength of the electromagnet depends on the number of coils. Describe the relationship.
Answer: More coils → stronger electromagnet (more paper clips attracted). [1]
(b) Besides increasing coils, state two other ways to increase the strength.
Answer: Increase voltage (add batteries in series), use soft iron core (not steel), increase current (thicker wire). (Any two) [2]
(c) Why is soft iron used as the core instead of steel?
Answer: Soft iron magnetises and demagnetises quickly (temporary magnet); steel retains magnetism (permanent magnet) → cannot switch off easily. [1]
Question 38 [4]
Diagram: Three beakers with equal water volume at 80°C. Different materials: Metal cup, Plastic cup, Styrofoam cup. Temperature recorded every 2 minutes.
(a) Which cup will show the fastest drop in temperature?
Answer: Metal cup. [1]
(b) Explain your answer in (a).
Answer: Metal is a good conductor of heat → transfers heat from hot water to surroundings fastest. [1]
(c) The experiment is repeated with lids on all cups. How will this affect the results?
Answer: Temperature drop slower in all cups; lid reduces heat loss by convection and evaporation. [1]
(d) Name the process of heat transfer that occurs through the cup material.
Answer: Conduction. [1]
Question 39 [4]
Diagram: Light ray hitting a plane mirror. Angle of incidence = 40°.
(a) What is the angle of reflection?
Answer: 40°. [1]
(b) The mirror is rotated 10° clockwise. What is the new angle of reflection?
Answer: 50° (angle of incidence increases by 10°). [1]
(c) State two characteristics of the image formed by a plane mirror.
Answer: Virtual, upright, same size, laterally inverted, same distance behind mirror as object in front. (Any two) [1]
(d) A periscope uses two plane mirrors. At what angle are the mirrors placed?
Answer: 45° to the horizontal / parallel to each other at 45°. [1]
Question 40 [4]
Diagram: Lever (see-saw) with fulcrum in middle. Girl (300 N) sits 2 m from fulcrum. Boy sits 1.5 m from fulcrum on other side.
(a) Calculate the moment exerted by the girl about the fulcrum.
Answer: Moment = Force × Distance = 300 N × 2 m = 600 Nm (clockwise). [1]
(b) What is the minimum weight of the boy needed to lift the girl?
Answer: For balance: Boy's weight × 1.5 m = 600 Nm → Weight = 400 N. To lift, > 400 N. [1]
(c) If the boy weighs 500 N, which side will tilt down?
Answer: Boy's side (anticlockwise moment = 500 × 1.5 = 750 Nm > 600 Nm). [1]
(d) State one way to reduce the effort needed to lift a load using a lever.
Answer: Increase effort arm length (move effort further from fulcrum) / decrease load arm length. [1]
Question 41 [4]
Diagram: Ball thrown upwards. Positions: A (launch), B (max height), C (falling down). Forces shown.
(a) At position B (maximum height), what is the velocity of the ball?
Answer: Zero (momentarily at rest). [1]
(b) At position B, what force(s) act on the ball? (Ignore air resistance.)
Answer: Only gravity (weight) acting downwards. [1]
(c) As the ball falls from B to C, its speed ________ (increases/decreases). Why?
Answer: Increases. Gravity accelerates it downwards. [1]
(d) Energy conversion: At A, ________ energy → At B, ________ energy → At C, ________ energy.
Answer: Kinetic → Gravitational potential → Kinetic (+ some heat/sound on impact). [1]
Question 42 [4]
Diagram: Solar panel → Battery → LED light. Energy conversion chain.
(a) Complete the energy conversion:
Sunlight → ________ energy (in solar panel) → ________ energy (in battery) → ________ energy + ________ energy (in LED).
Answer: Electrical → Chemical → Light + Heat. [2]
(b) Why is the LED not 100% efficient?
Answer: Some electrical energy is converted to heat (wasted). [1]
(c) State one advantage of using solar energy.
Answer: Renewable / no pollution / free source / reduces fossil fuel use. [1]
MARKING SCHEME SUMMARY
- Section A: 28 questions × 2 marks = 56 marks
- Section B: 14 questions (29–42) = 44 marks
- Total: 100 marks
End of Answer Key
Free quiz and exam paper access
Enter your details to view this paper
Your access is remembered on this device.