From Real Exams Quiz
Primary 4 Chinese Writing Quiz
Free P4 Chinese Writing quiz, Nemo3 Exam version, with questions, answers, and syllabus-aligned practice for Singapore students.
These static practice materials are generated from the site's syllabus and paper-generation workflow, with source and model context shown so students and parents can evaluate the material before use.
Questions
Primary 4 Chinese Quiz - Writing
Name: ________________________
Class: Primary 4 ________
Date: ________________________
Score: ________ / 40
Duration: 45 minutes
Total Marks: 40
Instructions:
- This quiz tests your writing skills in Chinese.
- Answer all questions in the spaces provided.
- Write neatly in Chinese characters.
- For composition questions, write at least 80-100 characters.
Section A: Sentence Construction and Expansion (10 marks)
Questions 1-5: Expand the given sentences by adding appropriate details. Write the complete sentence in the space provided. (2 marks each)
-
妹妹在公园里玩。
-
爸爸做了一道菜。
-
我们去图书馆借书。
-
弟弟弄坏了玩具。
-
老师表扬了同学。
Section B: Picture Description (10 marks)
Questions 6-10: Look at the picture and write one complete sentence for each question. Use the helping words given. (2 marks each)

Generated figure for Q6.
-
(帮助词:一家人、野餐、公园)
-
(帮助词:爸爸、烤肉、香)
-
(帮助词:哥哥、风筝、飞得高)
-
(帮助词:妹妹、喂、鸭子、开心)
-
(帮助词:天气、好、大家、快乐)
Section C: Guided Writing - Complete the Paragraph (10 marks)
Questions 11-15: Read the passage and fill in each blank with a complete sentence that fits the context. (2 marks each)
今天是星期天,天气晴朗,微风轻拂。我和爸爸妈妈一起去植物园游玩。________________________________________________________________ (11)
我们沿着小路走,两旁种满了各种花草树木。________________________________________________________________ (12)
突然,我看见一只可爱的松鼠在树枝上跳来跳去。________________________________________________________________ (13)
爸爸拿出相机,________________________________________________________________ (14)
我们在植物园度过了愉快的一天,________________________________________________________________ (15)
Section D: Situational Writing (10 marks)
Questions 16-20: Write a short message (留言条) based on the situation below. Include all required information. (2 marks each)
Situation: You are Li Ming (李明). Your mother is not at home. You need to write a note to tell her that you have gone to your classmate Xiao Hong's (小红) house to do homework together. You will be back by 6 pm. You have eaten your lunch. Remind her not to worry.
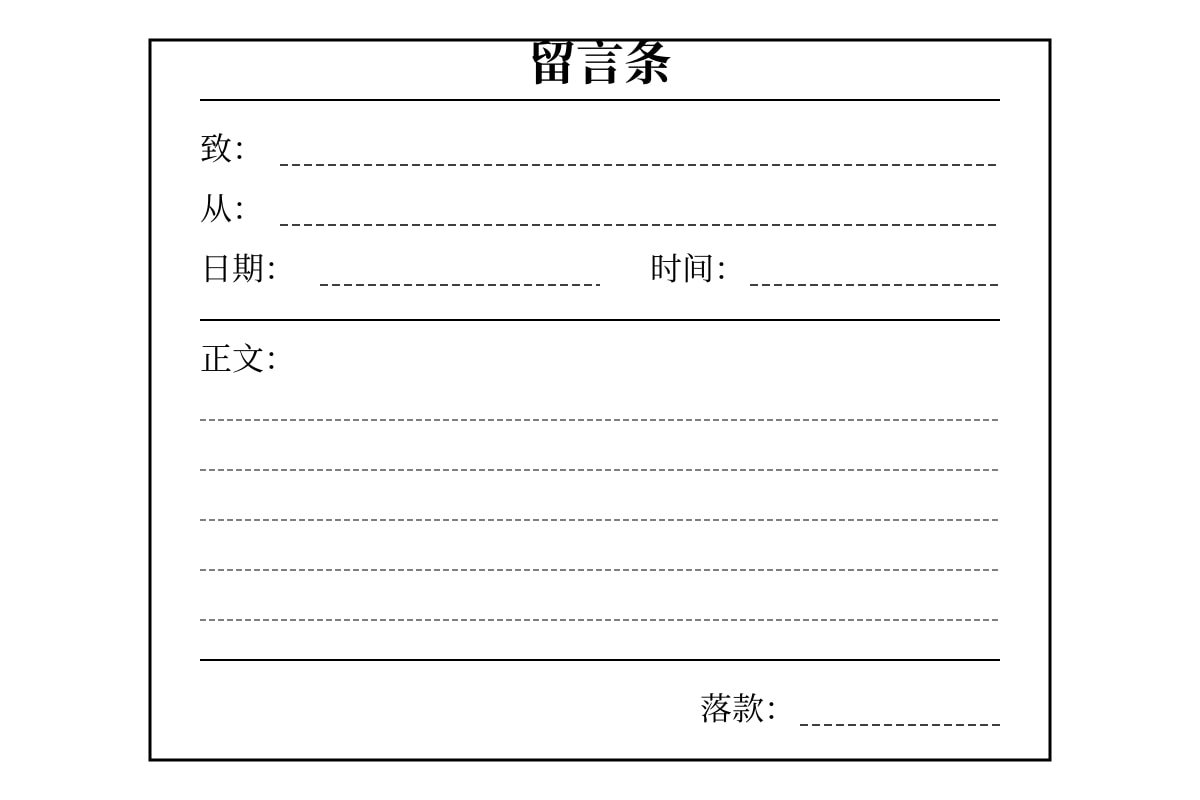
Generated table for Q16.
- Write the title of the note (标题):
- Write the recipient (致):
- Write the sender (从):
- Write the date and time (日期和时间):
- Write the body content (正文内容) - include all required information:
End of Quiz
Answers
Primary 4 Chinese Quiz - Writing (Answer Key)
Total Marks: 40
Section A: Sentence Construction and Expansion (10 marks)
Marking Guide: 1 mark for grammatical correctness and complete sentence structure; 1 mark for meaningful, relevant added details (time, place, manner, reason, etc.). Accept any logical expansion.
-
Sample Answer: 妹妹在公园里开心地玩滑梯。
Alternative: 昨天下午,妹妹在公园里和朋友一起玩得很开心。
Marks: 2 (1 for complete sentence, 1 for added detail) -
Sample Answer: 爸爸昨晚做了一道香喷喷的红烧肉。
Alternative: 爸爸为了庆祝妈妈生日,特意做了一道拿手菜。
Marks: 2 -
Sample Answer: 我们每个星期六都去图书馆借故事书。
Alternative: 放学后,我们一起去图书馆借书看。
Marks: 2 -
Sample Answer: 弟弟不小心弄坏了最喜欢的玩具车,哭了起来。
Alternative: 弟弟因为太用力,把玩具弄坏了。
Marks: 2 -
Sample Answer: 老师当着全班同学的面表扬了认真完成作业的同学。
Alternative: 老师表扬了同学,鼓励大家向他学习。
Marks: 2
Section B: Picture Description (10 marks)
Marking Guide: 1 mark for using all helping words correctly; 1 mark for complete, grammatically correct sentence that accurately describes the picture.
-
Answer: 一家人在公园野餐。
Helping words used: 一家人、野餐、公园 ✓
Marks: 2 -
Answer: 爸爸烤的肉很香。
Helping words used: 爸爸、烤肉、香 ✓
Marks: 2 -
Answer: 哥哥的风筝飞得很高。
Helping words used: 哥哥、风筝、飞得高 ✓
Marks: 2 -
Answer: 妹妹喂鸭子,喂得很开心。
Helping words used: 妹妹、喂、鸭子、开心 ✓
Marks: 2 -
Answer: 天气很好,大家都很快乐。
Helping words used: 天气、好、大家、快乐 ✓
Marks: 2
Section C: Guided Writing - Complete the Paragraph (10 marks)
Marking Guide: 1 mark for logical coherence with context; 1 mark for complete sentence with correct grammar and punctuation. Accept varied but appropriate responses.
-
Sample Answer: 我们带上了野餐垫和美味的食物。
Reasoning: Follows "去植物园游玩" - natural preparation action.
Marks: 2 -
Sample Answer: 空气中飘着淡淡的花香,让人心旷神怡。
Reasoning: Describes surroundings along the path (两旁种满了各种花草树木).
Marks: 2 -
Sample Answer: 我轻手轻脚地走过去,生怕吓跑了它。
Reasoning: Natural reaction to seeing a squirrel (松鼠在树枝上跳来跳去).
Marks: 2 -
Sample Answer: 为我和松鼠拍下了一张珍贵的合照。
Reasoning: Follows "爸爸拿出相机" - purpose of taking out camera.
Marks: 2 -
Sample Answer: 我下次还想再来这里玩。
Reasoning: Concluding thought after "度过了愉快的一天".
Marks: 2
Section D: Situational Writing (10 marks)
Marking Guide: Each sub-question 2 marks. For Q20 (body): 1 mark for including all 4 required points (gone to Xiao Hong's house, doing homework together, back by 6pm, eaten lunch); 1 mark for polite tone and correct format (including "别担心" / "不用担心").
-
Answer: 留言条
Marks: 2 -
Answer: 致:妈妈 / 亲爱的妈妈
Marks: 2 -
Answer: 从:李明 / 儿子 李明
Marks: 2 -
Answer: 日期:2024年X月X日 (今天的日期) 时间:下午X时X分
Note: Accept any reasonable current date/time.
Marks: 2 -
Sample Answer:
妈妈,我去小红家一起做功课了。我已经吃过午餐了。我会在下午六点前回家,您别担心。
李明Required points check:
- 去小红家 ✓
- 一起做功课 ✓
- 六点前回家 ✓
- 吃过午餐 ✓
- 别担心 ✓
Marks: 2
Common Mistakes to Avoid
- Section A: Writing sentence fragments instead of complete sentences. Always check for subject + predicate.
- Section B: Missing helping words or changing their form (e.g., using "飞高" instead of "飞得高").
- Section C: Writing sentences that don't flow logically from the previous/next sentence. Read the whole paragraph first.
- Section D: Forgetting the signature (落款) or date/time in situational writing. Format matters!
- General: Missing punctuation marks (。,!). Every sentence must end with proper punctuation.
Total: 40 marks
Free quiz and exam paper access
Enter your details to view this paper
Your access is remembered on this device.